Fundamentals of Graphical Communication
Overview: Perception & Cognitive Psych

The Eye
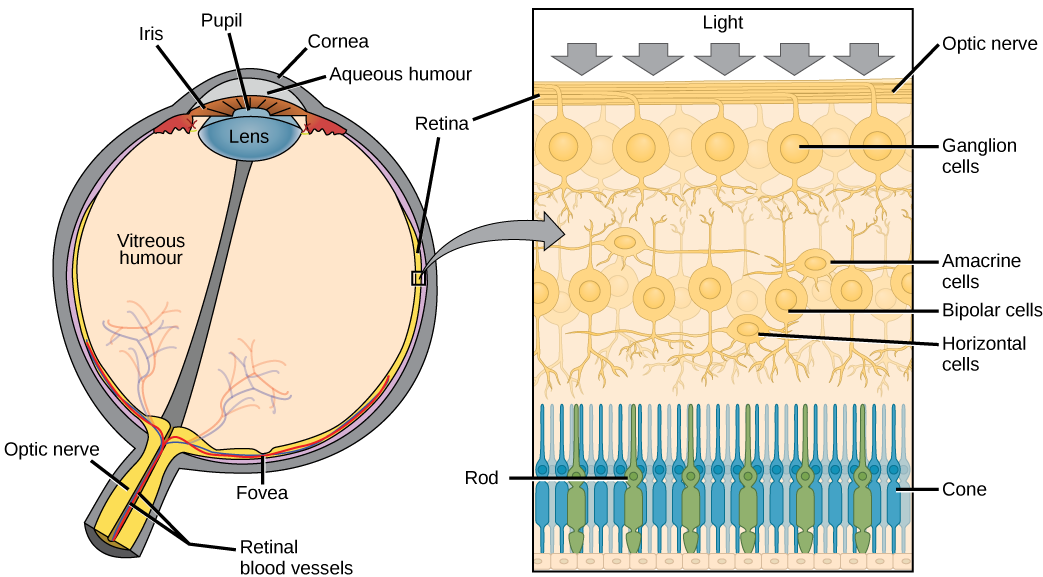
Figure 1: The human eye, with closeup of receptor cells in the retina. Image Source License Authors: OpenStax Copyright Holders: Rice University Publishers: OpenStax OpenStax Biology
Color Vision

Figure 2: Absorption spectra of rods and short (blue), medium (green), and long (red) wave cones. Image modified from Pancrat’s Wikimedia Commons work. License.
Object Perception

Preattentive Perception (Color)

Preattentive Perception (Shape)

Preattentive Perception (Interference)

Preattentive Perception (Dual Encoding)

Information Integration
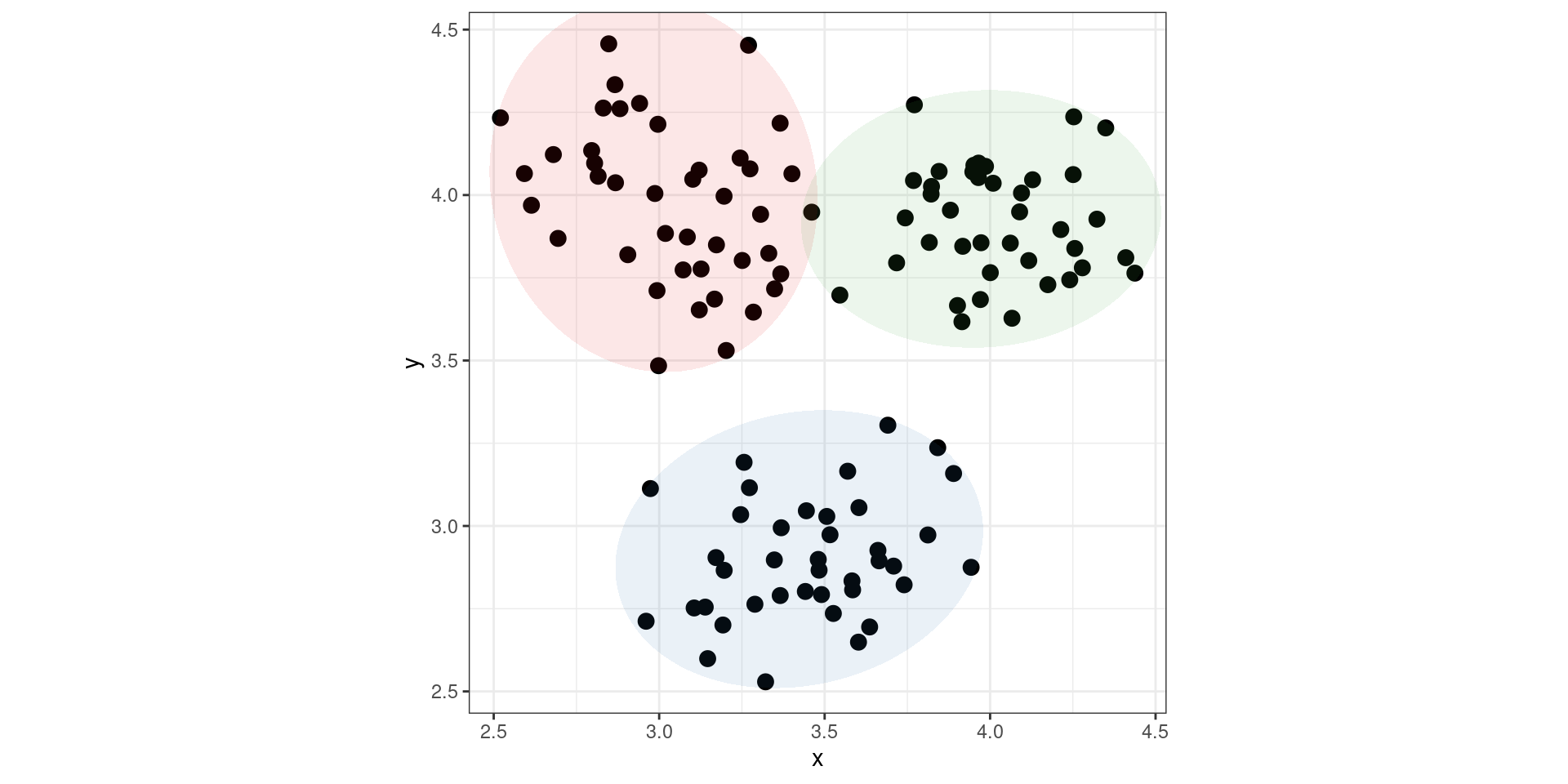
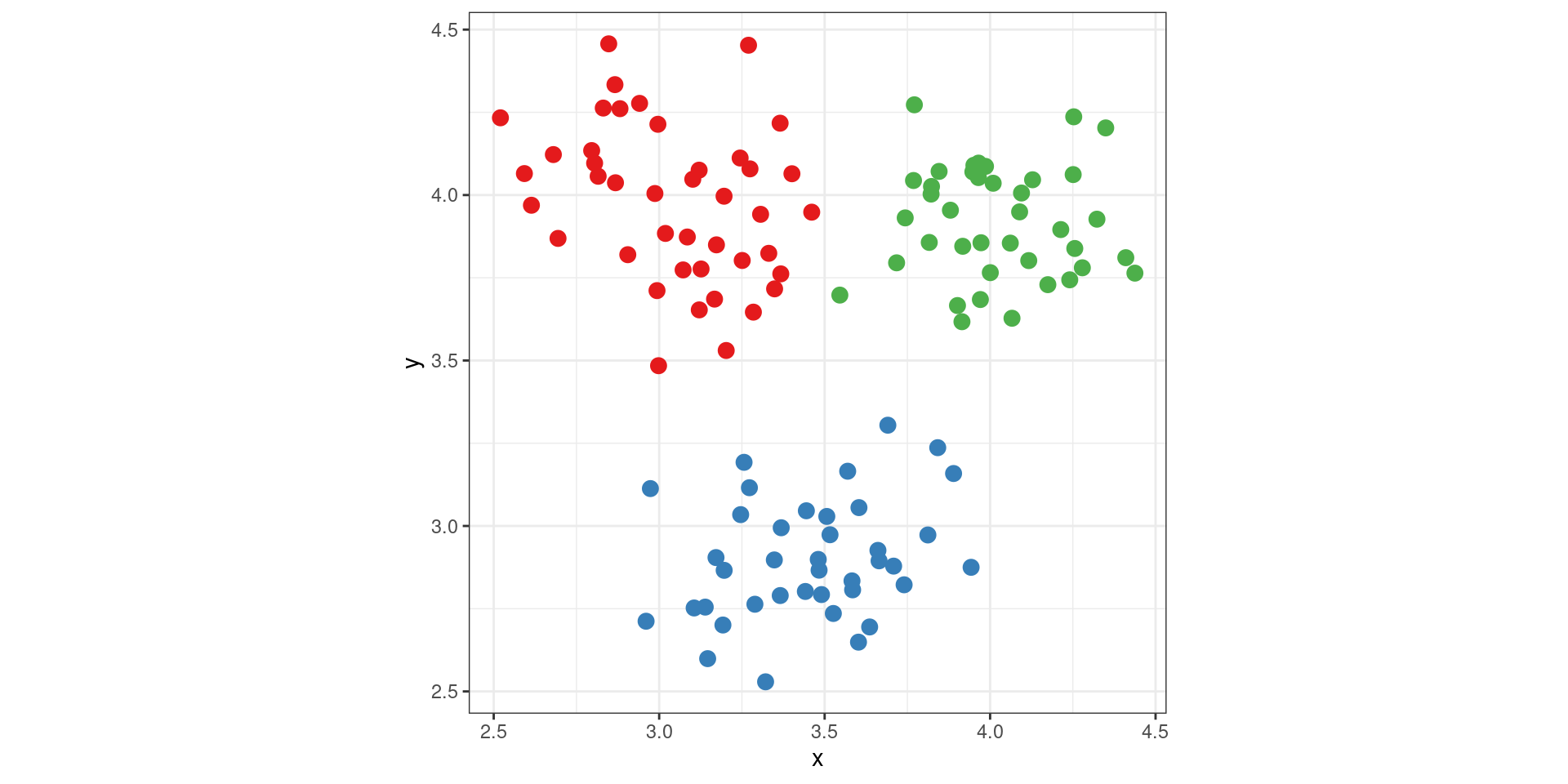
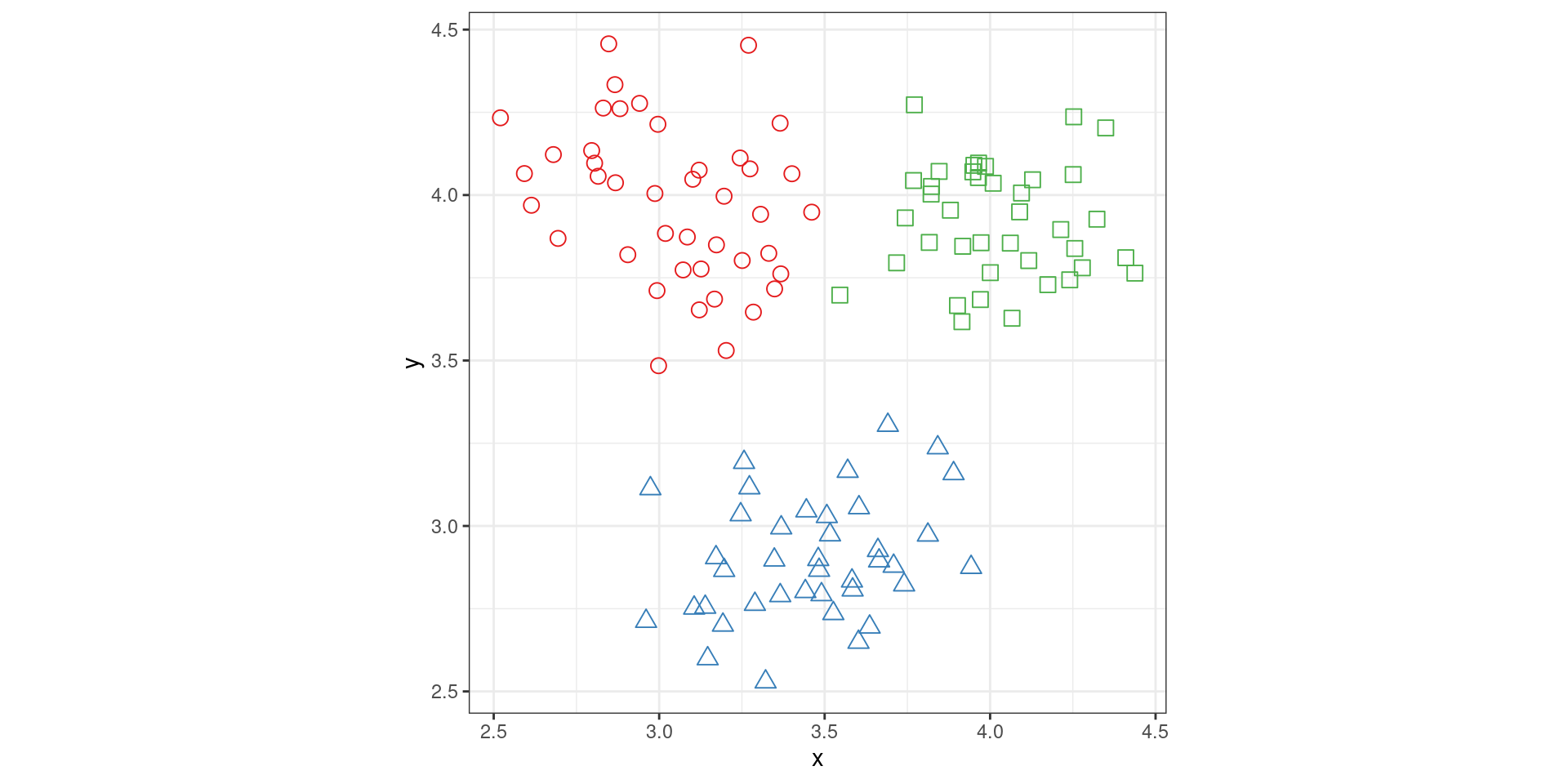
A note about graphical conventions
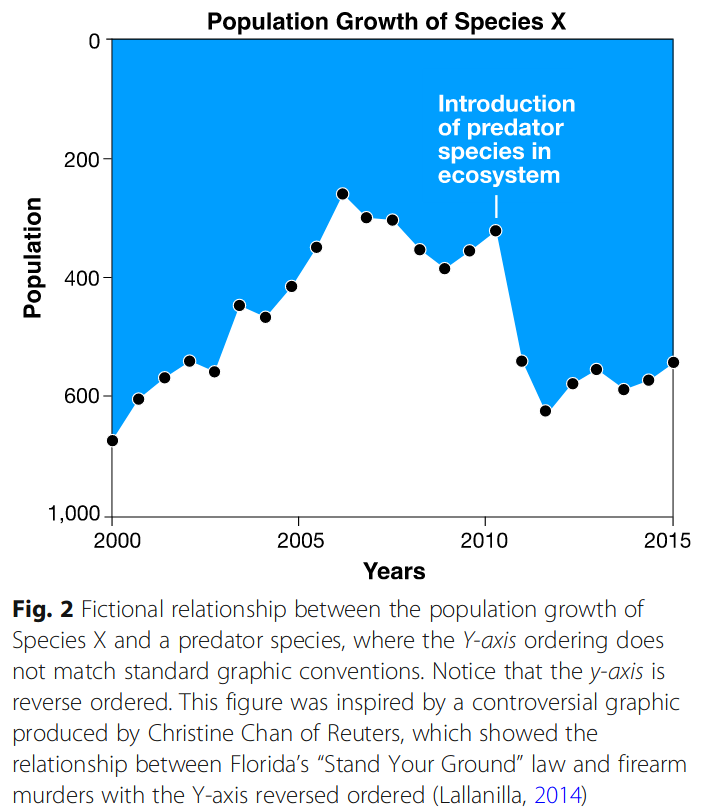
Image source: Padilla et al. (2018)
Example – Palmer Penguin Species
Palmer Penguin data collected by species. What is the average number of Adelie and Chinstrap Penguins measured? What steps do you go through to calculate this average?
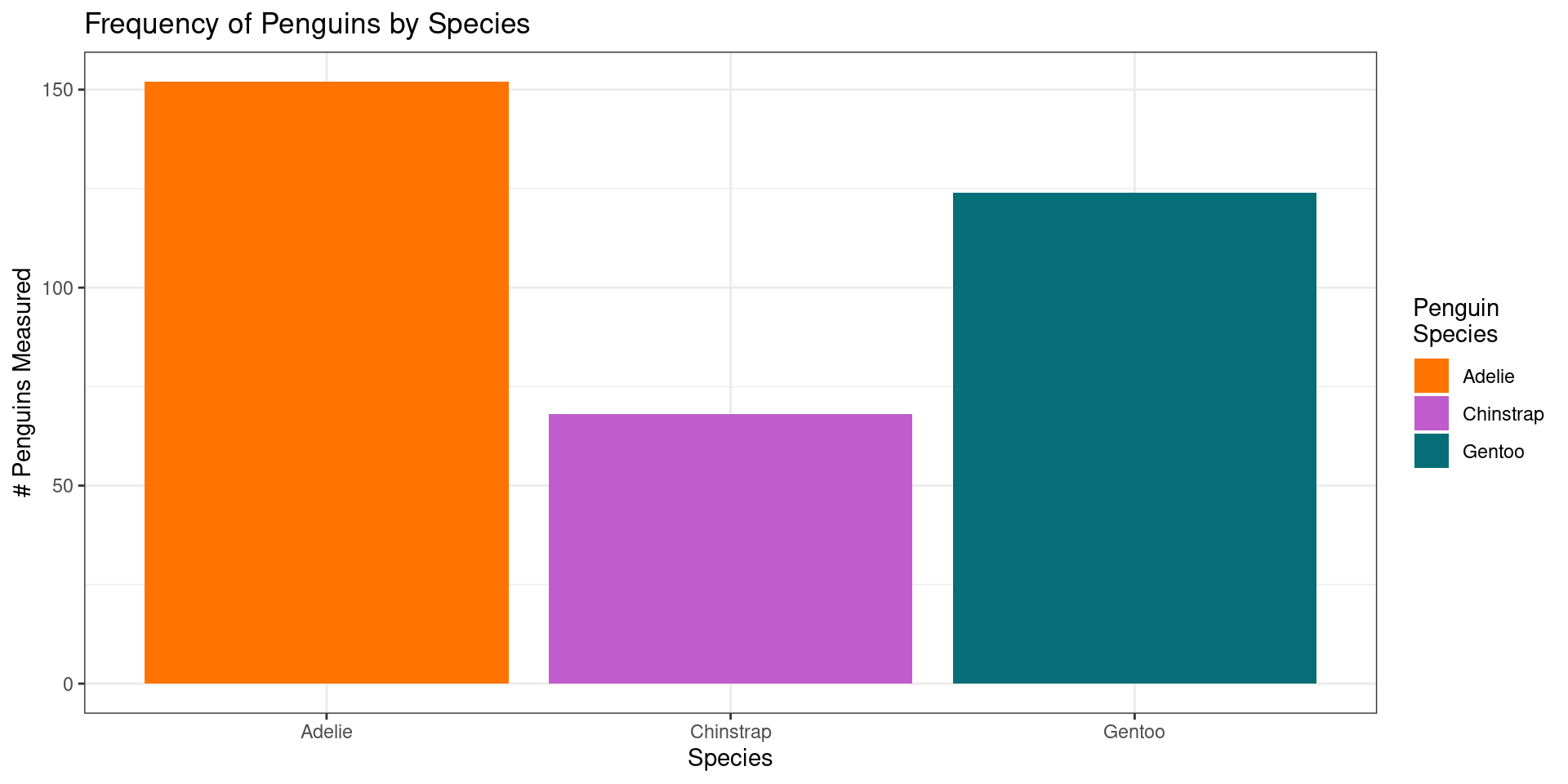
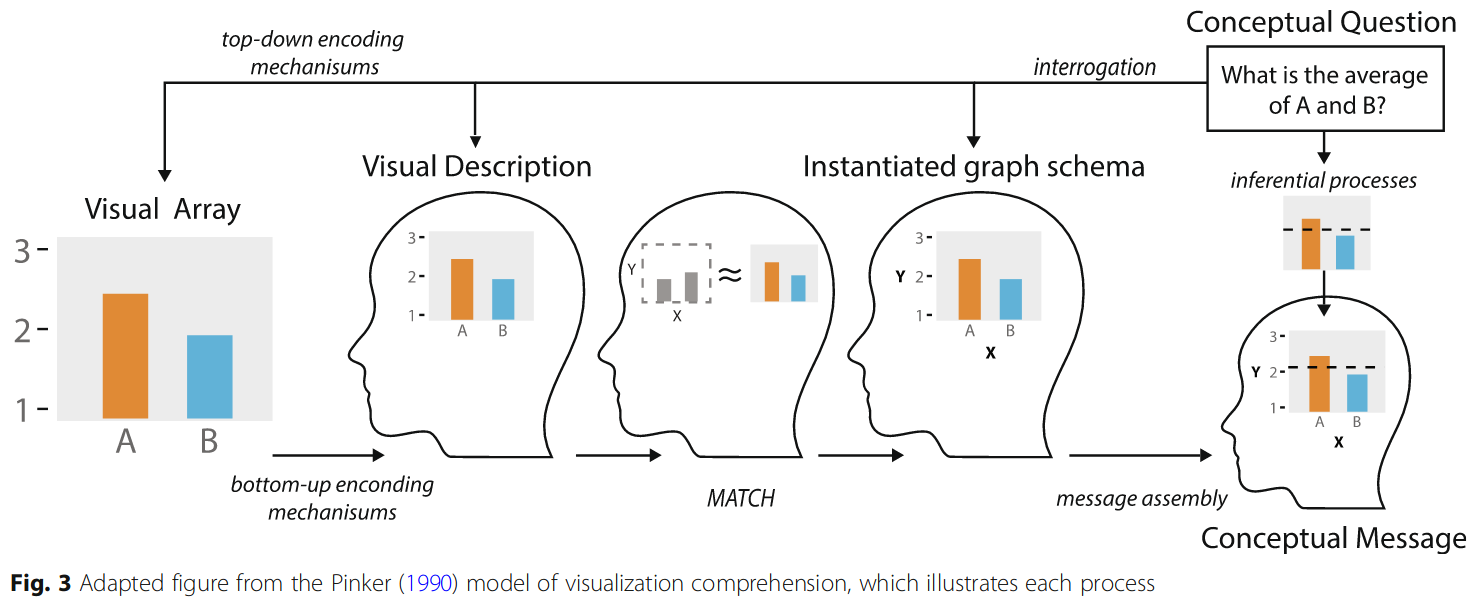
Image source: Padilla et al (2018), an adaptation of Pinker (1990)
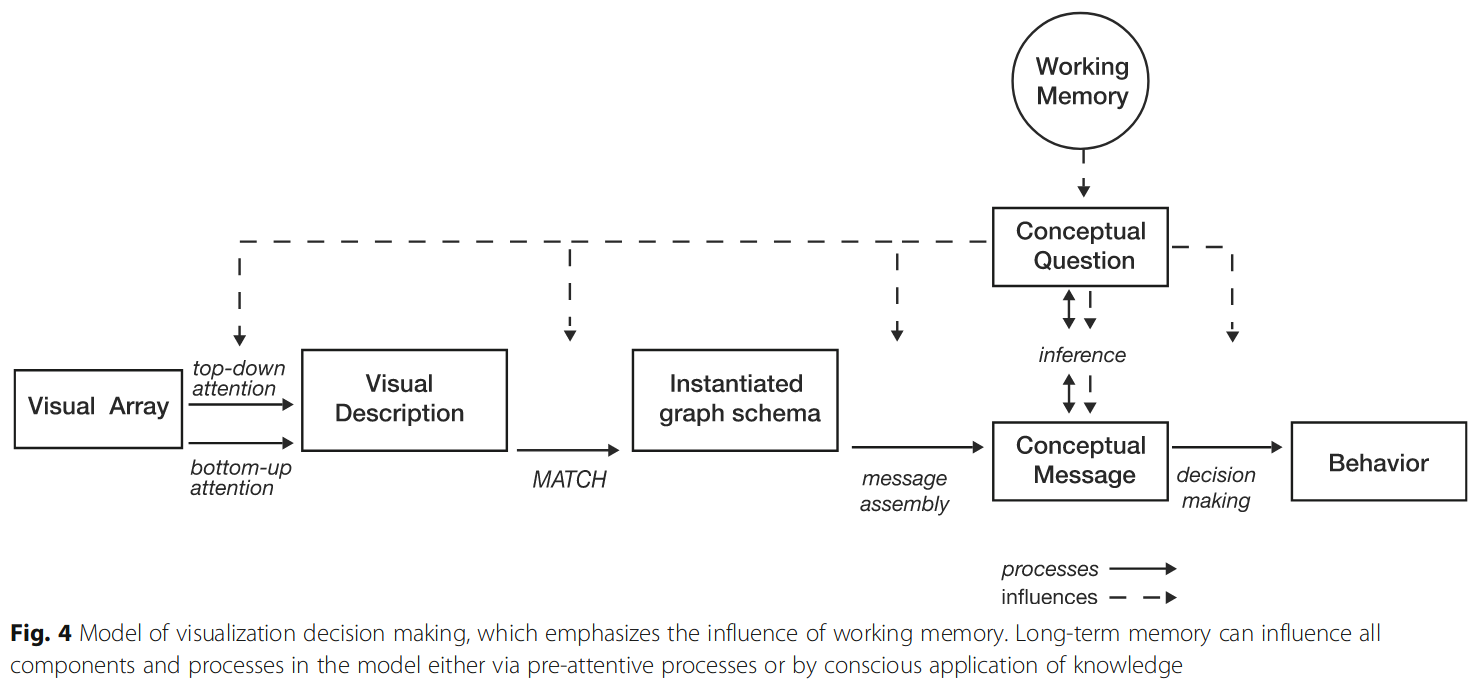
Image source: Padilla et al. (2018)
Example – Palmer Penguin Species



{kind=link}
{kind=link}
A (not very good) starting point…
Code
# a pretty bad start
richmond_childcare |>
filter(county_name == "Richmond County") |>
ggplot(aes(x = study_year,
y = median_weekly_childcare_cost,
fill = development_stage
)
) +
geom_bar(stat = "identity",
position = "dodge") +
facet_wrap(~ center_type) +
scale_x_continuous(limits = c(2008, 2018),
breaks = seq(2008, 2018, 2)
) +
scale_y_continuous(labels = scales::dollar) +
scale_fill_manual(values = c("#ff7400", "#c05ccb", "#056e76")) +
labs(x = "Study Year",
y = "Median Weekly Childcare Cost",
fill = "Development Stage") +
theme_bw()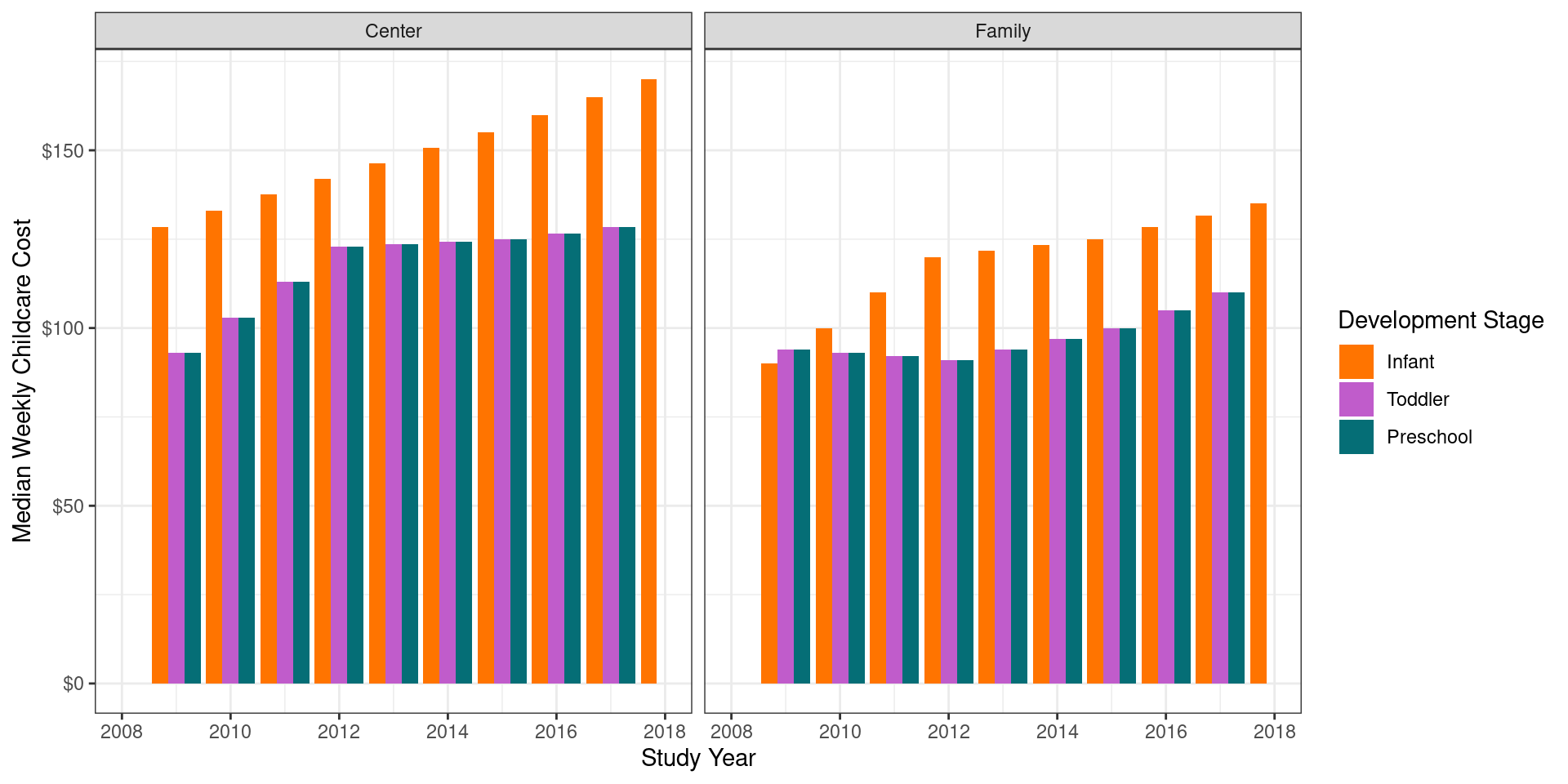
Code
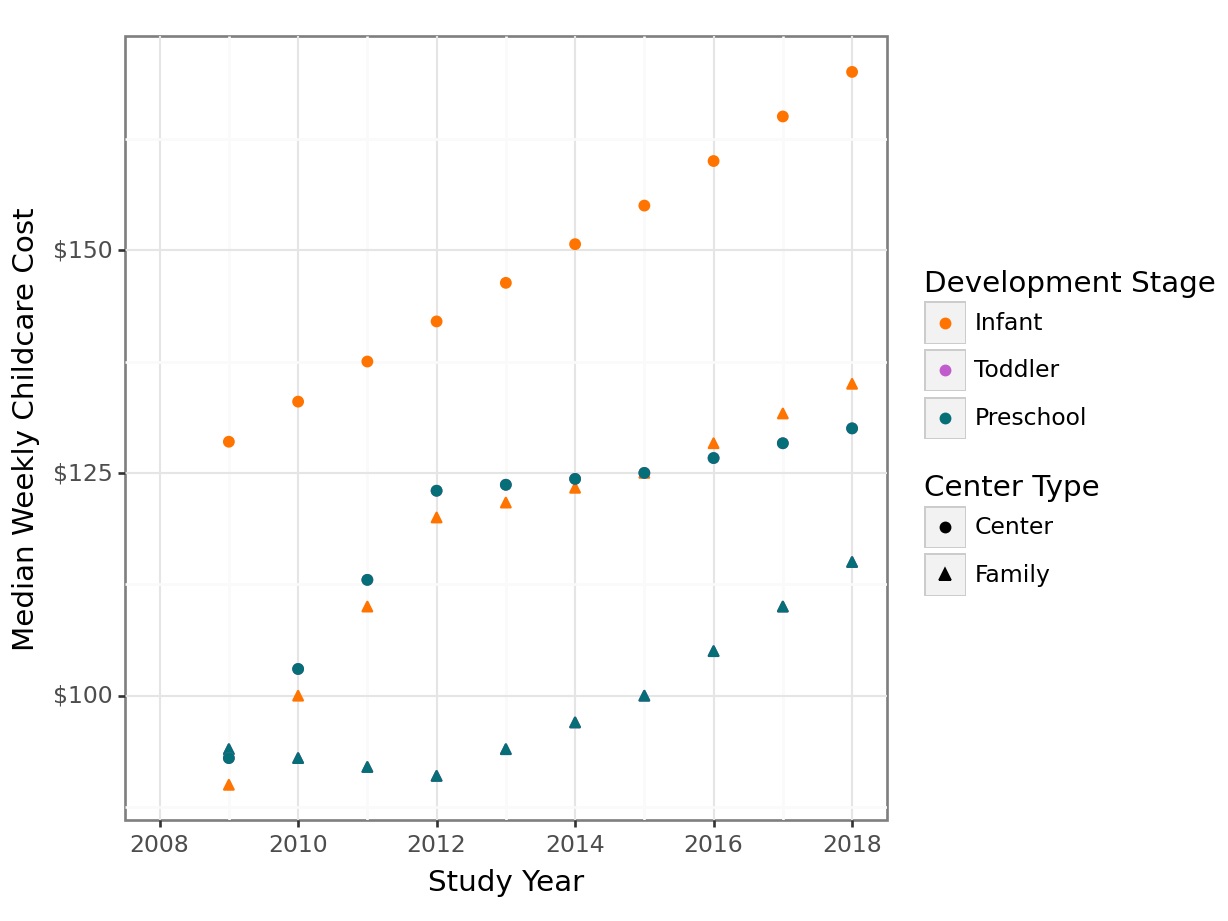
# a slightly better start?
richmond_childcare |>
filter(county_name == "Richmond County") |>
ggplot(aes(x = study_year,
y = median_weekly_childcare_cost,
color = development_stage,
shape = center_type
)
) +
geom_point() +
scale_x_continuous(limits = c(2008, 2018),
breaks = seq(2008, 2018, 2)
) +
scale_y_continuous(labels = scales::dollar) +
scale_color_manual(values = c("#ff7400", "#c05ccb", "#056e76")) +
labs(x = "Study Year",
y = "Median Weekly Childcare Cost",
color = "Development Stage",
shape = "Center Type") +
theme_bw()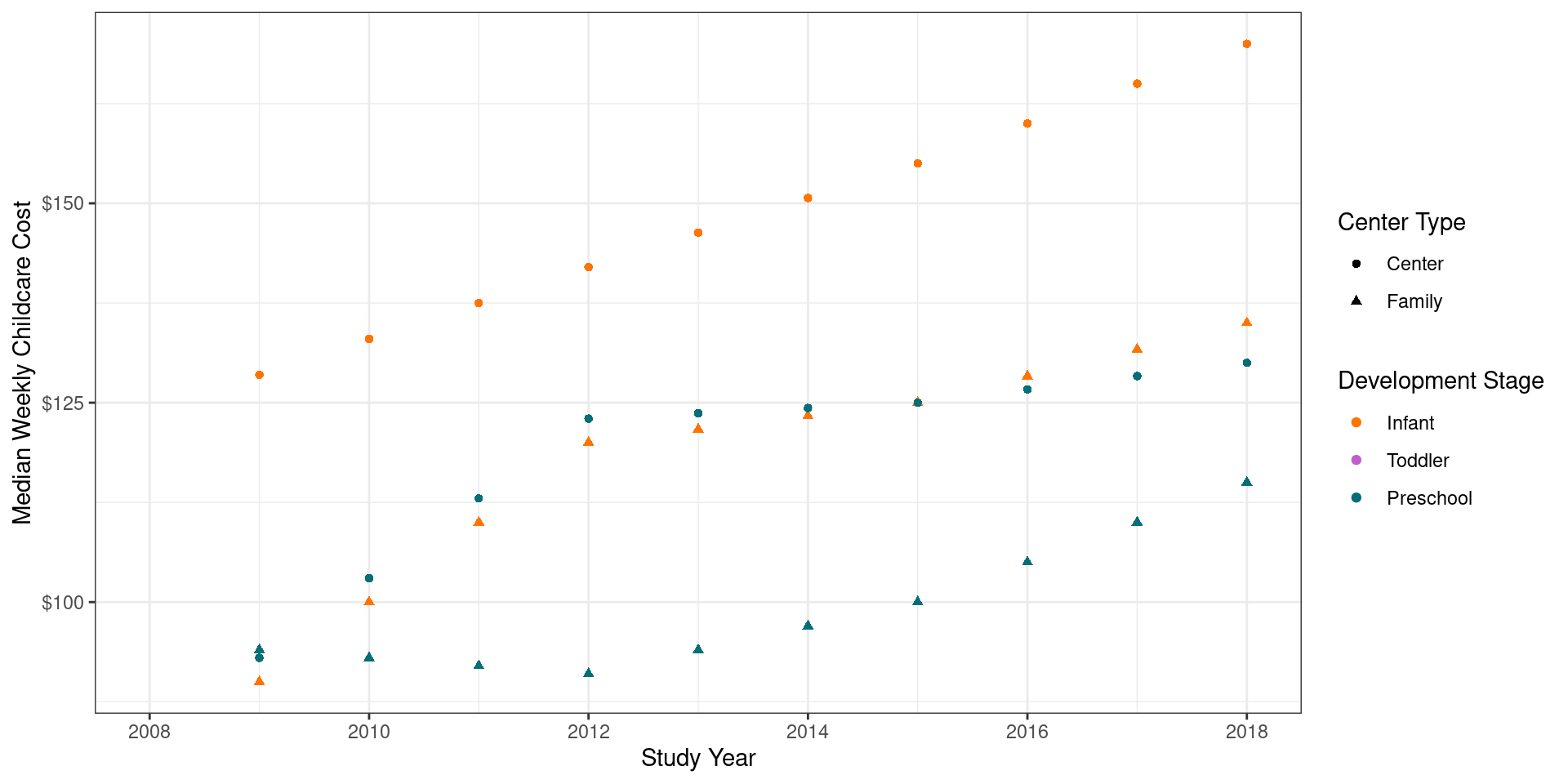
Code
import pandas as pd
from plotnine import *
import requests
# Read in the data
url = "https://raw.githubusercontent.com/earobinson95/data-for-download/main/richmond-va-childcare.csv"
richmond_childcare = pd.read_csv(url)
# Reorder the development stages
richmond_childcare['development_stage'] = pd.Categorical(
richmond_childcare['development_stage'],
categories=["Infant", "Toddler", "Preschool"],
ordered=True
)
# First plot: Bar plot
p1 = (ggplot(richmond_childcare, aes(x='study_year',
y='median_weekly_childcare_cost',
fill='development_stage')) +
geom_bar(stat='identity', position='dodge') +
facet_wrap('~center_type') +
scale_x_continuous(limits=(2008, 2018), breaks=range(2008, 2019, 2)) +
scale_y_continuous(labels=lambda l: ["${:,.0f}".format(v) for v in l]) +
scale_fill_manual(values=["#ff7400", "#c05ccb", "#056e76"]) +
labs(x="Study Year", y="Median Weekly Childcare Cost", fill="Development Stage") +
theme_bw()
)
print(p1)
# Second plot: Scatter plot
/home/susan/.virtualenvs/r-reticulate/lib/python3.11/site-packages/plotnine/layer.py:364: PlotnineWarning: geom_bar : Removed 4 rows containing missing values.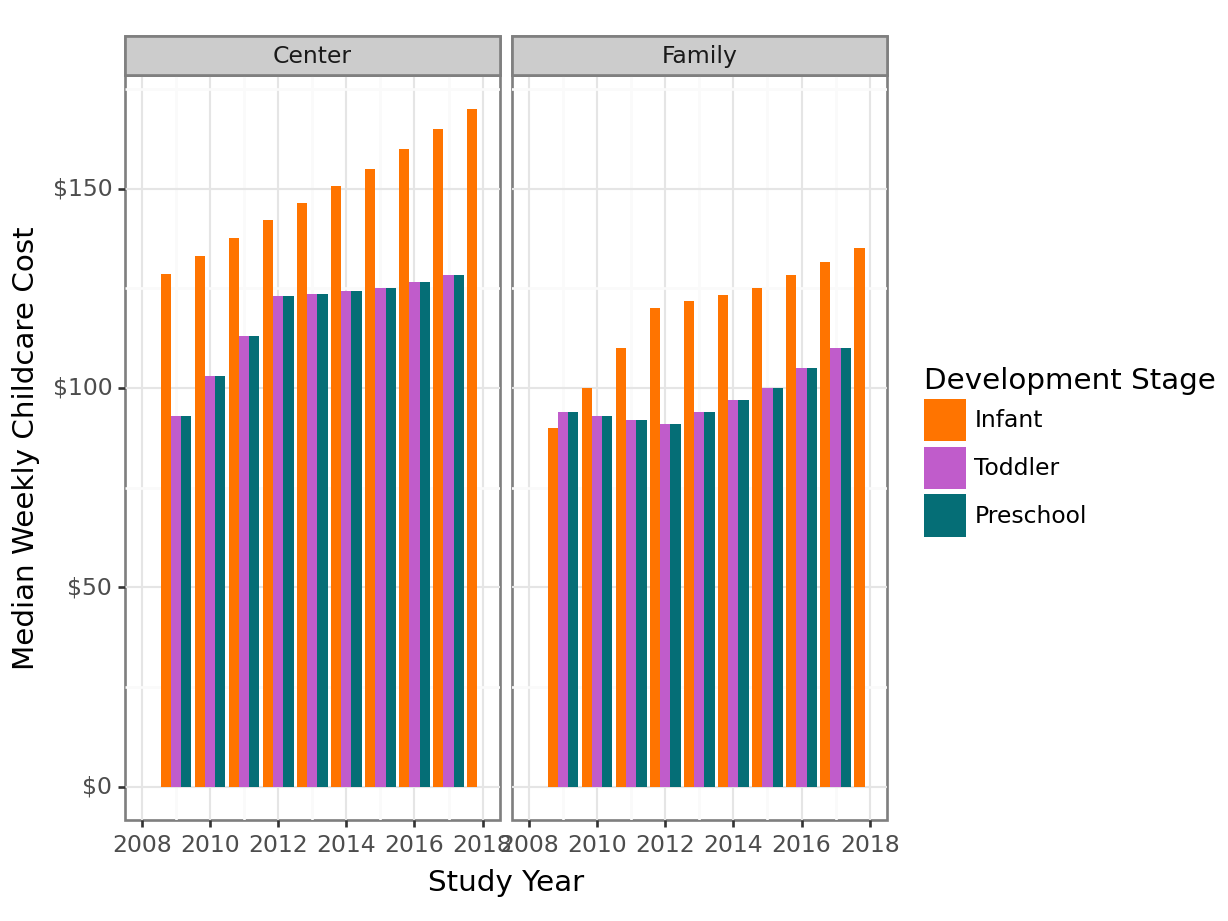
Code
p2 = (ggplot(richmond_childcare, aes(x='study_year',
y='median_weekly_childcare_cost',
color='development_stage',
shape='center_type')) +
geom_point() +
scale_x_continuous(limits=(2008, 2018), breaks=range(2008, 2019, 2)) +
scale_y_continuous(labels=lambda l: ["${:,.0f}".format(v) for v in l]) +
scale_color_manual(values=["#ff7400", "#c05ccb", "#056e76"]) +
labs(x="Study Year", y="Median Weekly Childcare Cost", color="Development Stage", shape = "Center Type") +
theme_bw()
)
print(p2)