“Far better an approximate answer to the right question, which is often vague, than an exact answer to the wrong question, which can always be made precise.”
— John Tukey
Guiding Questions
What does this data have to tell me about the topic?
Is the data reliable?
Is the data complete?
How are the variables distributed?
How are the variables related?
Question Generation
Does the structure of the data match your expectations?
Did the data read in correctly?
How does the data fit in context?
Do the observations make sense?
scale
missingness
relationships with other variables
Numerical EDA
Basic summary statistics
Made easier with tools like skimr and skimpy that tabulate summaries and sparkline charts
library(skimr)skim(new_data)
Numerical EDA
Data summary
Name
new_data
Number of rows
2142
Number of columns
3
_______________________
Column type frequency:
character
1
numeric
2
________________________
Group variables
None
Numerical EDA
var
n_missing
complete_rate
group
0
1
var
min
max
empty
n_unique
whitespace
group
1
1
0
13
0
Numerical EDA
var
n_missing
complete_rate
mean
sd
V1
150
0.9299720
54.24875
16.73711
V2
146
0.9318394
47.87741
26.94546
var
p0
p25
p50
p75
p100
hist
V1
15.5607495
40.89041
52.52804
67.32513
98.28812
▂▆▇▆▁
V2
0.0151193
22.19145
47.79891
71.97336
99.69468
▇▇▇▇▆
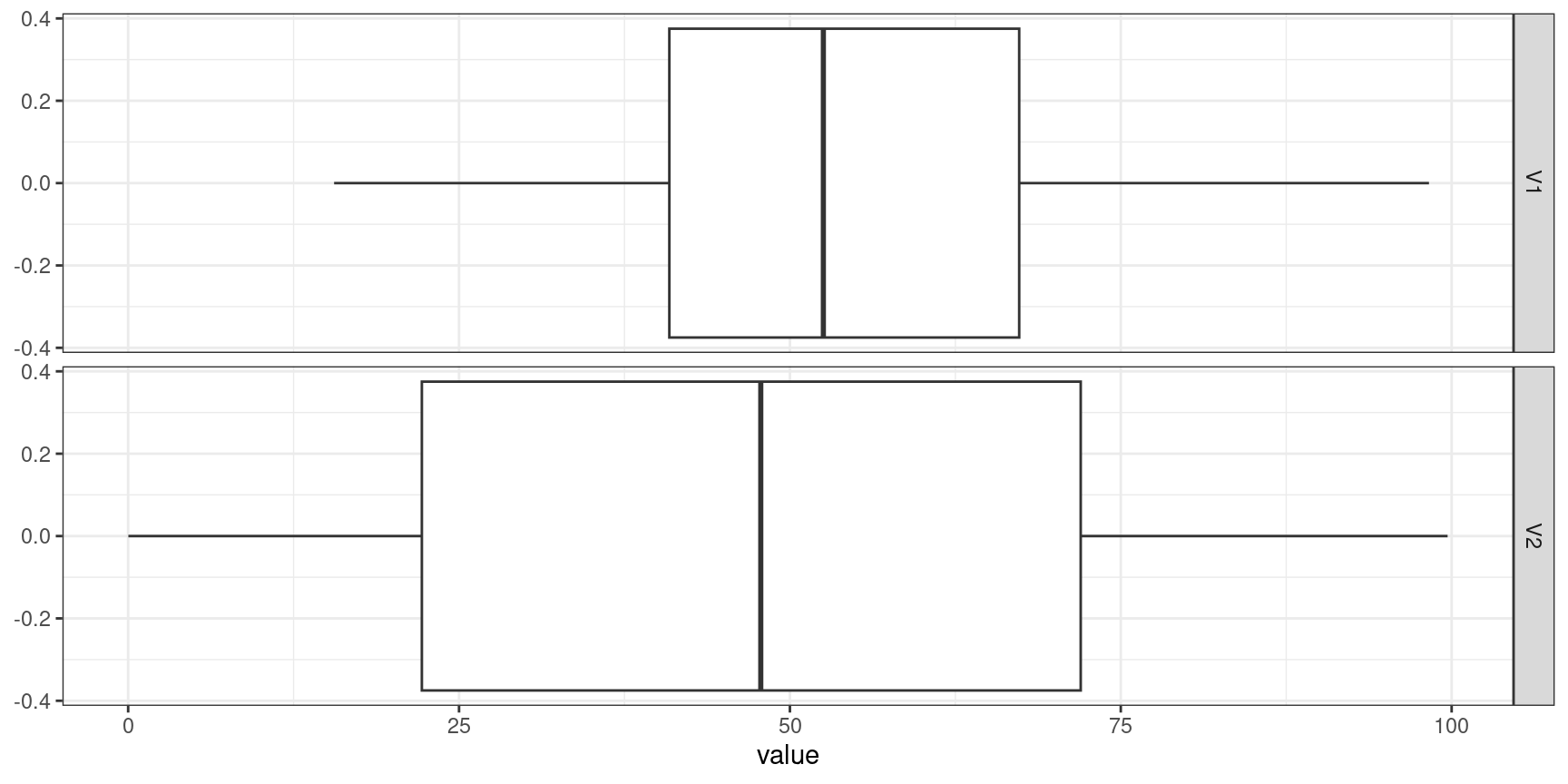
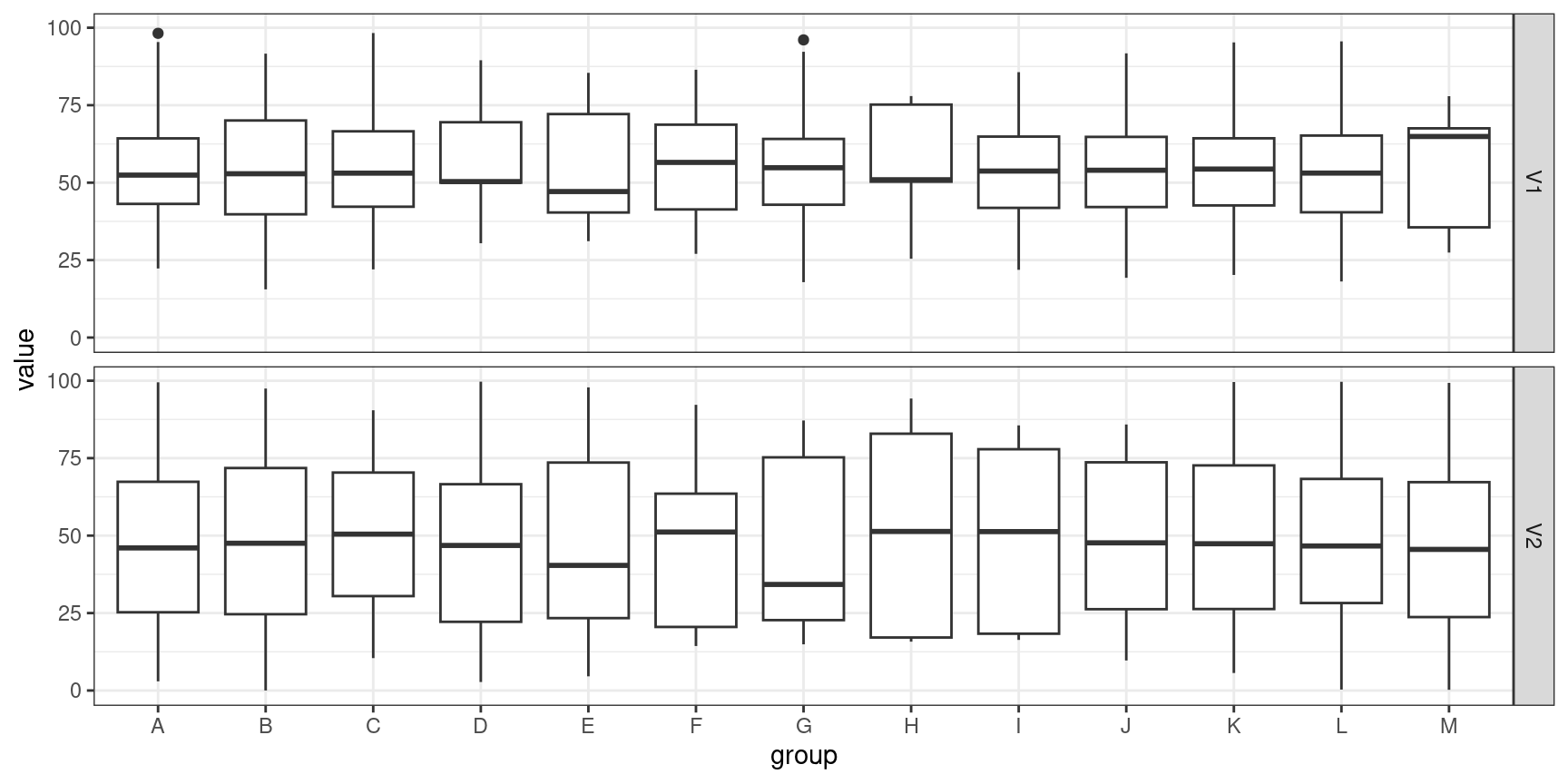
Graphical EDA
Start with single variables (1D summaries)
Add in factor variables (Conditional 1D summaries)
Move to 2D summaries and pairwise scatterplots
For high dimensional numerical data, consider dimension reduction techniques (PCA, t-SNE, UMAP)
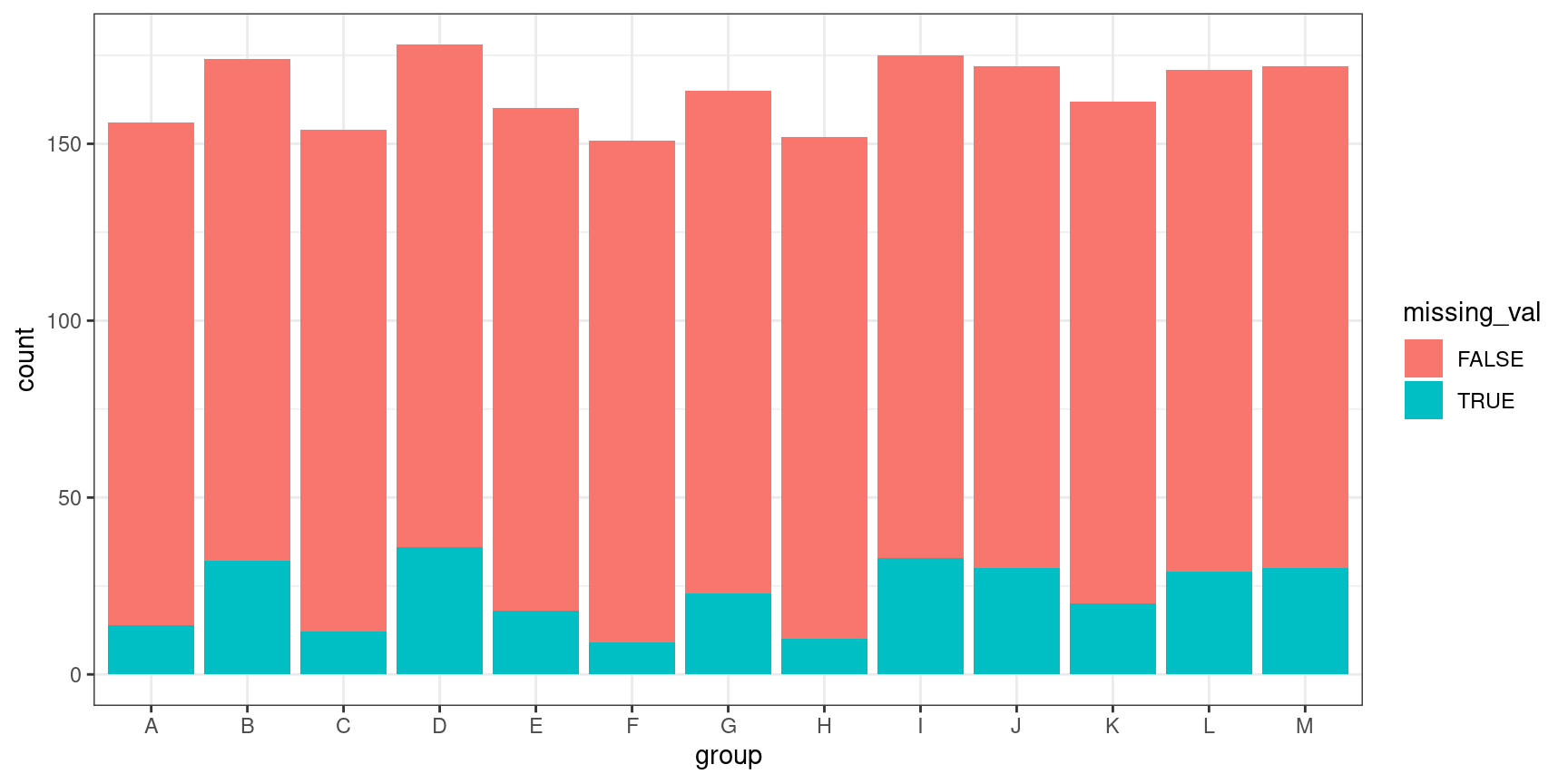
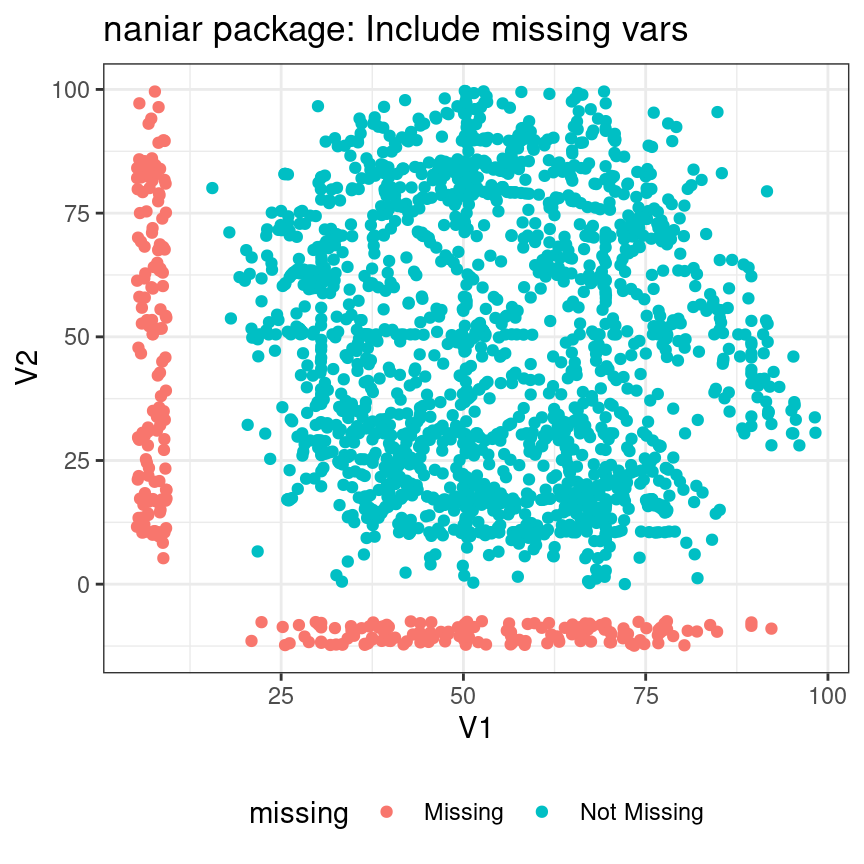
Be careful to notice/account for missing values
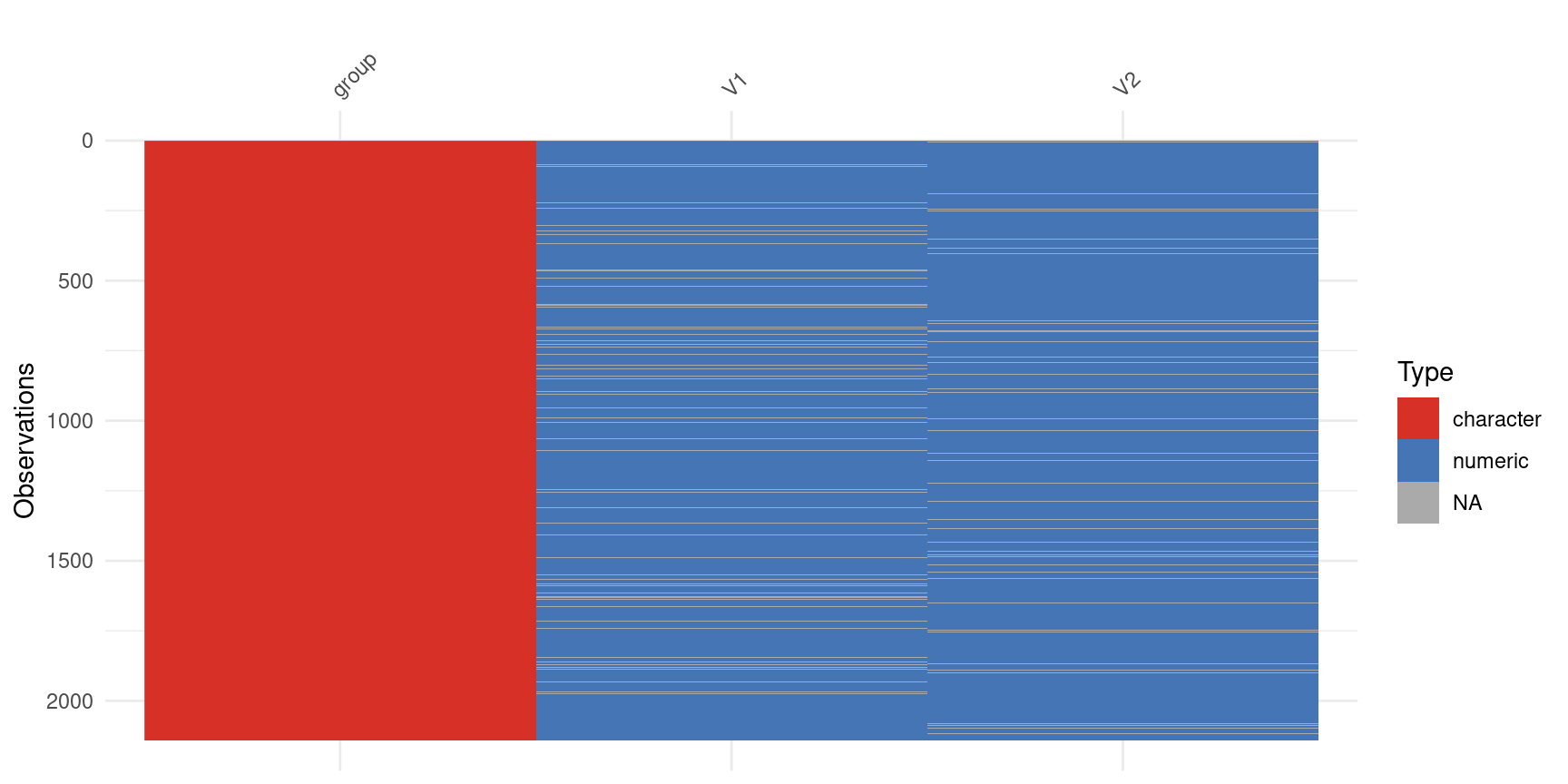
naniar and visdat R packages
missingno in python
Graphical EDA
library(visdat)vis_dat(new_data) +# Make color values a bit more colorblind friendlyscale_fill_manual(values =c("#d73027", "#4575b4"), na.value ="#AAAAAA")