{kind=link}

A chart is good if it allows the user to draw useful conclusions that are supported by data. Obviously, this definition depends on the purpose of the chart. A simple and disposable chart created during an exploratory data analysis process may be useful even if it is not nicely formatted and publication ready, because its purpose is to guide an interactive process. This is very different than a chart created for communicating with the public – for instance, a forecast map showing possible paths and intensities of a hurricane that would inform resident decisions about storm preparation and/or evacuation.
Comprehensive advice on creating good charts is difficult, too, because what works for one dataset may not work for another, even if the variable types are similar. We have some established conventions that should usually be followed (for instance, time usually is placed on the x-axis, with a dependent variable on the y-axis), but there are usually situations where it is reasonable to break those conventions.
Finally, what makes a chart “good” requires some additional knowledge beyond statistics and programming. To make good charts, we have to understand how those charts will be interpreted, which means we need at least some basic information about human perception and cognition. The human visual system is incredibly powerful - it has a bandwidth that would make even modern computers jealous, and many computations are performed instantaneously and without requiring any process management (e.g. the calculations happen so fast and so automatically that you aren’t really aware that they’re happening). This comes with some tradeoffs, though - evolutionary optimizations that ensure that you can spot predators quickly weren’t as concerned with your ability to accurately determine the height of a two-dimensional drawing of a three-dimensional object. So, while the visual system has some amazing strengths and is a very useful medium to communicate about data, it is important to understand the limitations of the visual system’s sensors, software, short-term and long term memory, and attention.
We’ll start with a short exploration of some foundational concepts related to perception in Section 21.2. Section 21.3 will discuss the design process and how to leverage the grammar of graphics to provide both the full data and visual summaries that highlight key features. Where available, this section incorporates conclusions from empirical studies of charts and graphs to guide design decisions.
Section 21.3.3 expands on this discussion, demonstrating effective use of annotations to provide contextual information that can assist viewers with the interpretation of the data. Finally, Section 21.4 provides a guide to evaluating graphics for clarity, effectiveness, accessibility, and common design pitfalls.
Before we discuss how to create good charts, there is a certain amount of background information that must be considered. Charts make use of the visual system within the human brain, which means we need to understand some basic attributes of human perception and cognition in order to make the best use of this “wetware” [1] processing power.
First, let’s set the stage. Information in the form of light bounces off objects in the world and lands on our retina (there are lenses and focusing mechanisms that we’ll skip). There are four types of light detectors in the retina: three types of cones that respond to red, green, and blue light wavelengths, and rods, which respond to light intensity across wavelengths. Cones are concentrated in one area, while rods are spread across the surface of the retina. The rods and cones turn light into neural impulses, which are transmitted along the optic nerve to the visual cortex located in the back of the brain (roughly where your head would hit the floor when you are lying down). The visual cortex contains special neurons called feature detectors which organize the information from the retina and reconstruct this information into a mental representation of the world. Some feature detectors respond to specific angles, signals from specific parts of the retina corresponding to specific parts of the outside world, and many other low-level features. Signals from these feature detectors are then aggregated into higher-level concepts that form our visual experience of the world.
The initial light signals and lower-level information are sometimes called “sensation”, and the ability to detect higher-level concepts is called “perception”. We can also think of “top-down” perception, where our experience shapes what we perceive and how we experience the world, compared to “bottom-up” perception, where we construct higher-level concepts solely from lower-level signals.
Perception tends to require a few other mental resources beyond the visual detection and processing equipment (eyes, visual cortex, etc.): attention and memory (short and long-term) are vital for processing the visual input and making sense out of it. The next few subsections provide specific examples of why it’s important to understand the basics of the visual system when thinking about how to construct charts and graphs.
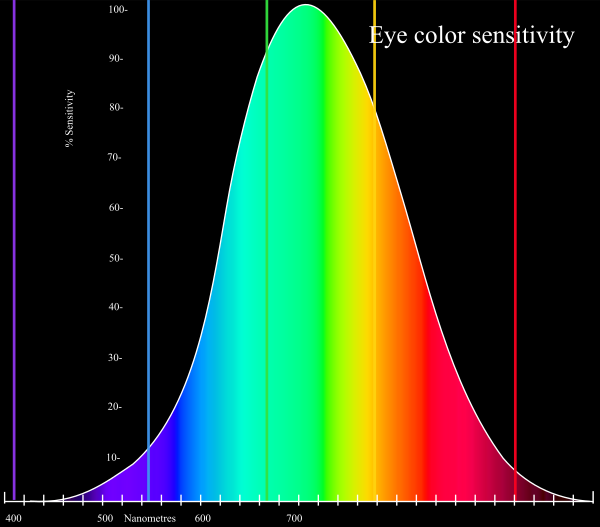
Our eyes are optimized for perceiving the yellow/green region of the color spectrum, as shown in Figure 21.1. Why? Well, our sun produces yellow light, and plants tend to be green. It’s pretty important to be able to distinguish different shades of green (evolutionarily speaking) because it impacts your ability to feed yourself. There aren’t that many purple or blue predators, so there is less selection pressure to improve perception of that part of the visual spectrum.
Not everyone perceives color in the same way. Some individuals are colorblind or color deficient [2]. We have 3 cones used for color detection, as well as cells called rods, which detect light intensity (brightness/darkness). In about 5% of the population (10% of XY individuals, 0.2% of XX individuals), one or more of the cones may be missing or malformed, leading to color blindness - a reduced ability to perceive different shades. The rods, however, function normally in almost all of the population, which means that light/dark contrasts are extremely safe, while contrasts based on the hue of the color are problematic in some instances.
Simulations of the same rainbow color scheme map under different types of colorblindness, generated using CoBliS. While colorblindness simulations can be useful, as colorblindness is a result of one of many different mutations, simulators do not cover all of the different color vision mutations which exist.
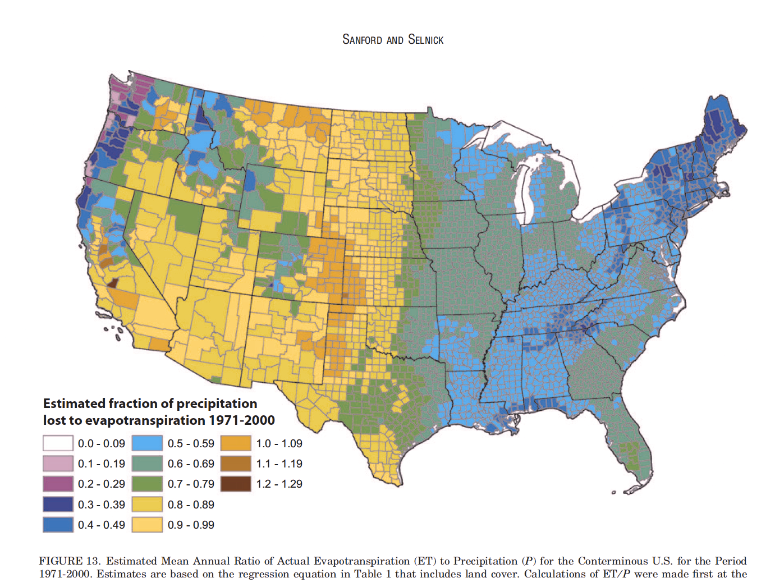
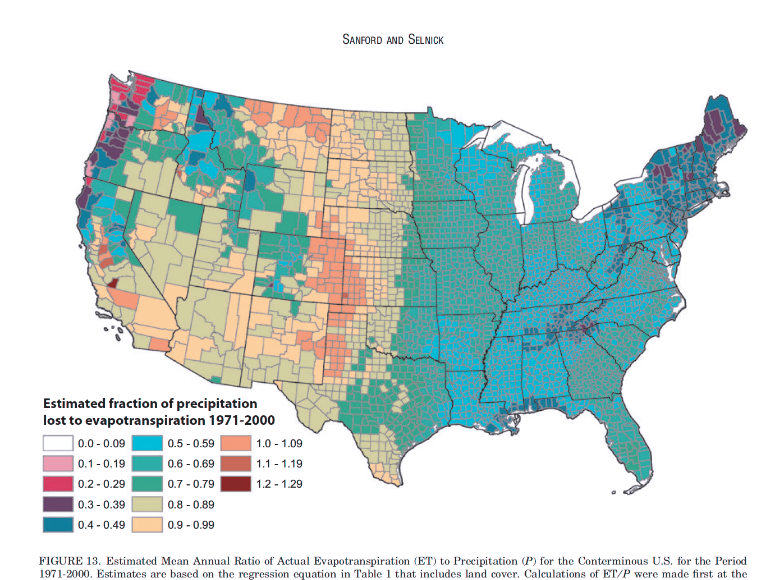
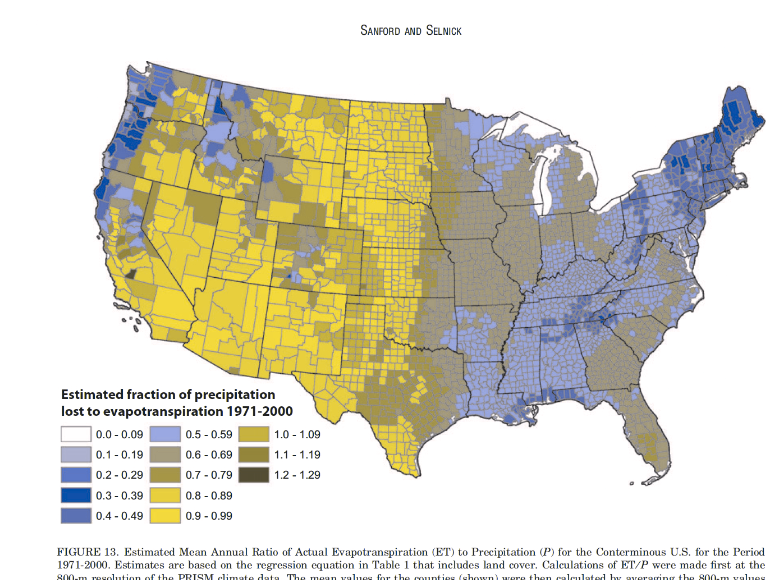
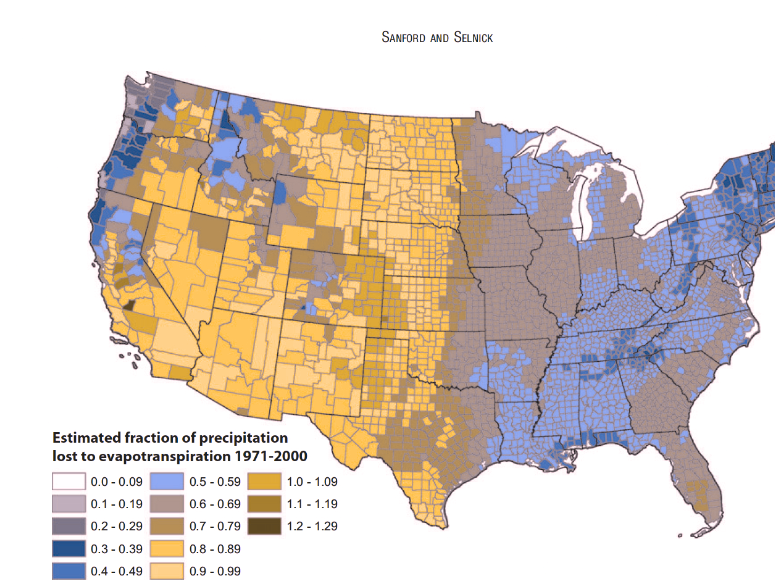
You can take a test designed to screen for colorblindness here. Your monitor may affect how you score on these tests - I am colorblind, but on some monitors, I can pass the test, and on some, I perform worse than normal. A different test is available here.


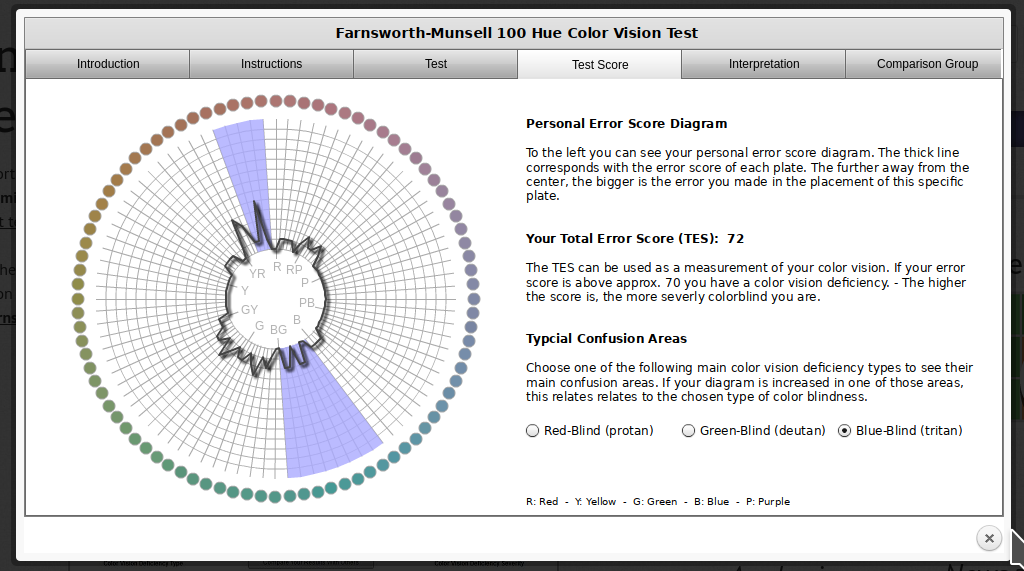
In reality, I know that I have issues with perceiving some shades of red, green, and brown. I have particular trouble with very dark or very light colors, especially when they are close to grey or brown.
In addition to colorblindness, there are other factors than the actual color value which are important in how we experience color, such as context.
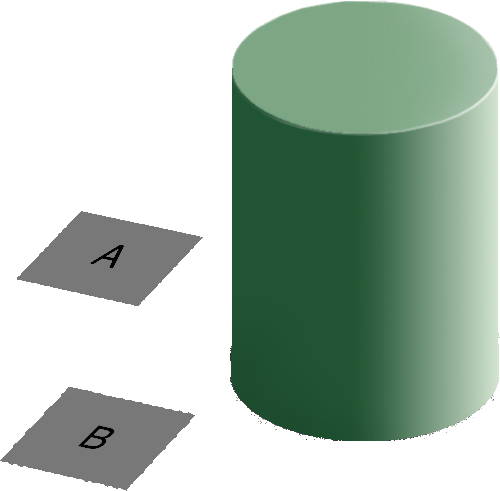
Our brains are extremely dependent on context and make excellent use of the large amounts of experience we have with the real world. As a result, we implicitly “remove” the effect of things like shadows as we make sense of the input to the visual system. This can result in odd things, like the checkerboard and shadow shown in Figure 21.9 - because the brain automatically corrects for the shadow, B looks lighter than A, even though when the context is removed they are clearly the same shade.
RColorBrewer and dichromat that have color palettes which are aesthetically pleasing, and, in many cases, colorblind friendly (dichromat is better for that than RColorBrewer). You can also take a look at other ways to find nice color palettes.You’ve almost certainly noticed that some graphical tasks are easier than others. Part of the reason for this is that certain tasks require active engagement and attention to search through the visual stimulus; others, however, just “pop” out of the background. We call these features that just “pop” without active work preattentive features; technically, they are detected within the first 250ms of viewing a stimulus [3].
Take a look at Figure 21.10; can you spot the point that is different?


Color and shape are commonly used graphical features that are processed pre-attentively. Some people suggest utilizing this to pack more dimensions into multivariate visualizations [4], but in general, knowing which features are processed more quickly (color/shape) and which are processed more slowly (combinations of preattentively processed features) allows you to design a chart that requires less cognitive effort to read.
As awesome as it is to be able to use preattentive features to process information, we cannot use combinations of preattentive features to show different variables - these combinations are no longer processed preattentively. Take a look at Figure 21.11 - part (a) shows the same grouping in color and shape, part (b) shows color and shape used to encode different variables.


Here, it is easy to differentiate the points in Figure 21.11(a), because they are dual-encoded. However, it is very difficult to pick out the different groups of points in Figure 21.11(b) because the combination of preattentive features requires active attention to sort out.
Careful use of preattentive features can reduce the cognitive effort required for viewers to perceive a chart.
Encode only one variable using preattentive features, as combinations of preattentive features are not processed preattentively.
We have a limited amount of memory that we can instantaneously utilize. This mental space, called short-term memory, holds information for active use, but only for a limited amount of time.
Without rehearsing the information (repeating it over and over to yourself), the try it out task may have been challenging. Short term memory has a capacity of between 3 and 9 “bits” of information.
In charts and graphs, short term memory is important because we need to be able to associate information from e.g. a key, legend, or caption with information plotted on the graph. If you try to plot more than ~6 categories of information, your reader will have to shift between the legend and the graph repeatedly, increasing the amount of cognitive labor required to digest the information in the chart.
Where possible, try to keep your legends to 6 or 7 characteristics.
Limit the number of categories in your legends to minimize the short term memory demands on your reader.
Use colors and symbols which have implicit meaning to minimize the need to refer to the legend.
Add annotations on the plot, where possible, to reduce the need to re-read captions.
The catchphrase of Gestalt psychology is
The whole is greater than the sum of the parts
That is, what we perceive and the meaning we derive from the visual scene is more than the individual components of that visual scene.
Our brains have to be very good at imposing order on visual chaos – there is a huge amount of information being processed by the visual system all the time, and some basic heuristics (guesses/shortcuts) are important in this process.
When we create charts, it becomes important to understand these heuristics so that we can make it easier for people to understand the data. Working with the natural sense making algorithms in the brain requires less cognitive effort, which leaves more space for thinking about the data.
Let’s start with a few examples that show how the brain constructs meaning from ambiguous or conflicting stimuli.
What does Figure 21.12 look like to you?
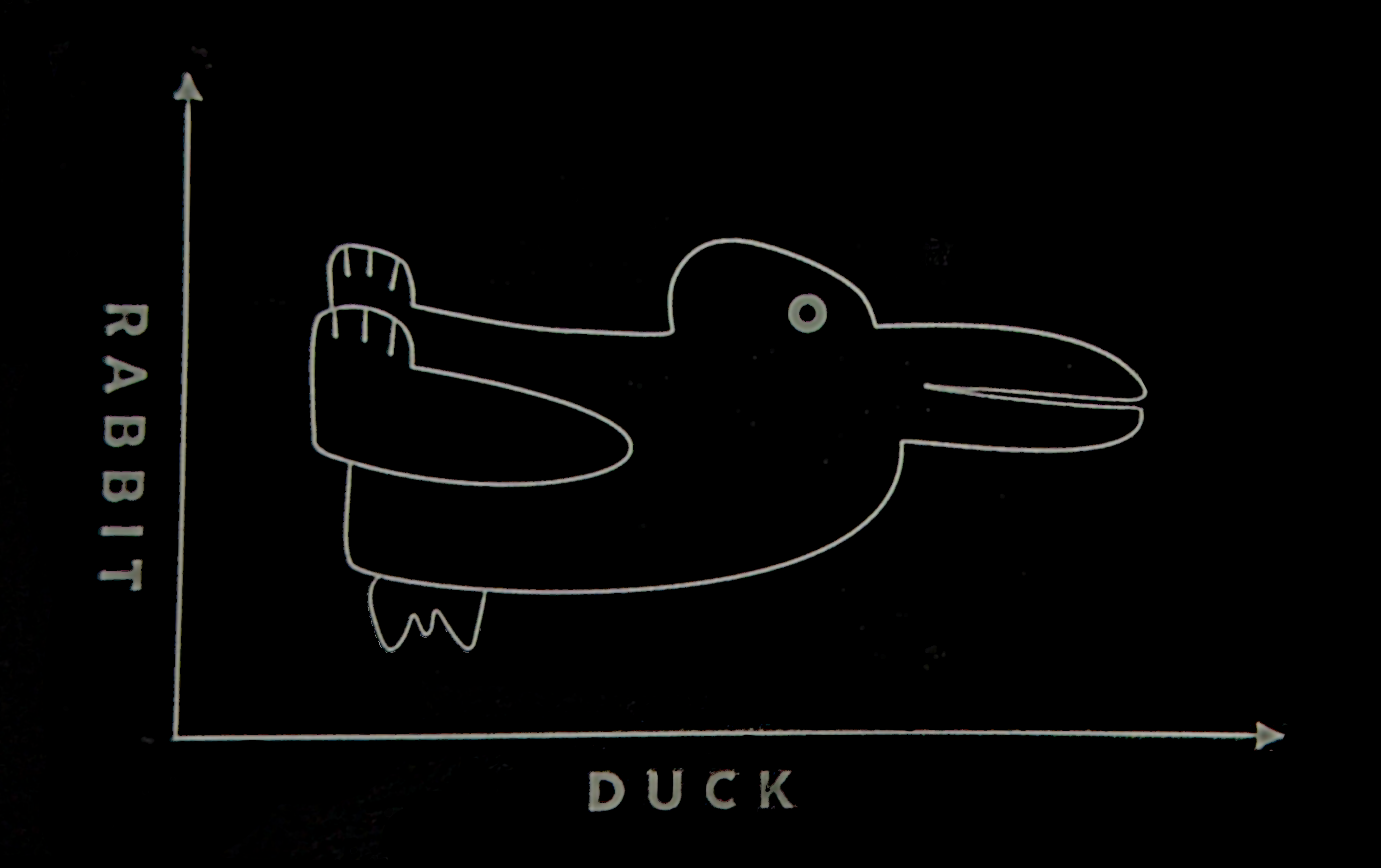
When faced with ambiguity, our brains use available context and past experience to try to tip the balance between alternate interpretations of an image. When there is still some ambiguity, many times the brain will just decide to interpret an image as one of the possible options. Sometimes, the brain will even flip between the possible options, as in the Necker cube illusion.
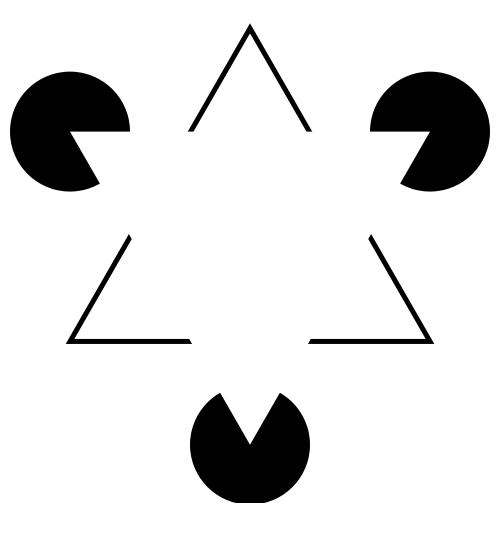
Did you see something like “3 circles, a triangle with a black outline, and a white triangle on top of that”? In reality, there are 3 angles and 3 pac-man shapes. But, it’s much more likely that we’re seeing layers of information, where some of the information is obscured (like the “mouth” of the pac-man circles, or the middle segment of each side of the triangle). This explanation is simpler, and more consistent with our experience.
This illusory contour image is closely related to the Gestalt concepts of closure and “good figure”.
Consider the logo for the Pittsburgh Zoo.
![]()
Do you see the gorilla and lionness? Or do you see a tree? Here, we’re not entirely sure which part of the image is the figure and which is the background.
One of the first tasks we have when confronted with a visual scene is to separate the important part of the image (the figure) from the background. In most cases this is straightforward, but occasionally, artificial images (as opposed to real world scenes) can be hard to interpret. The zoo logo shown above leverages this ambiguity to capture your visual attention.
The ambiguous figures shown above demonstrate that our brains are actively imposing order upon the visual stimuli we encounter.
The Gestalt heuristics attempt to explain how our brains group and order visual stimuli to make sense of the world. You can read about the gestalt rules here, but they are also demonstrated in Figure 21.13.
In graphics, we make use of the Gestalt principles of grouping to create order and meaning. If we color points by another variable, we are creating groups of similar points which assist with the perception of groups instead of individual observations. If we add a trend line, we create the perception that the points are moving “with” the line (in most cases), or occasionally, that the line is dividing up two groups of points. Depending on what features of the data you wish to emphasize, you might choose different aesthetics mappings, facet variables, and factor orders.
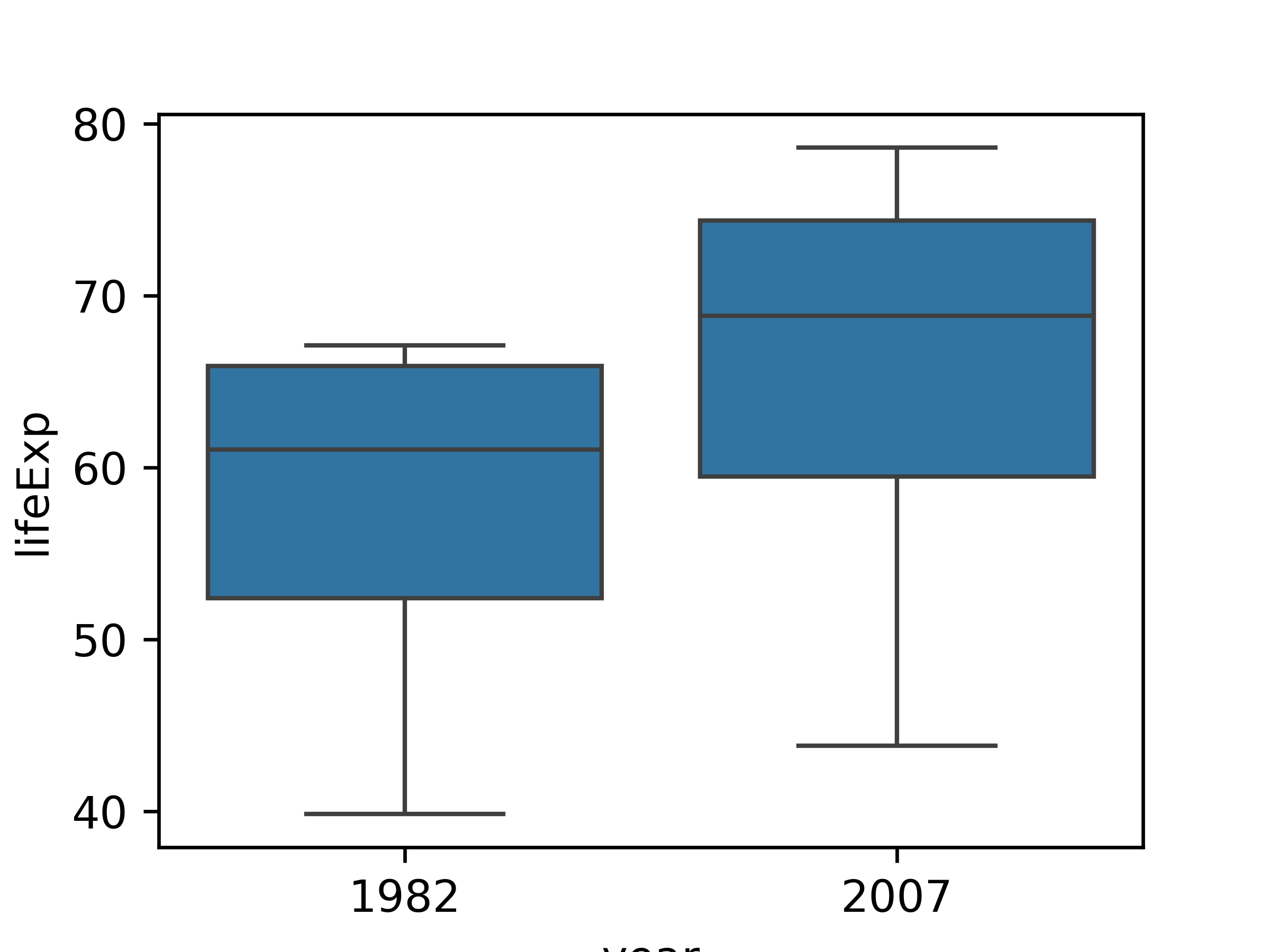
Suppose I want to emphasize the change in life expectancy between 1982 and 2007. For this, we’ll use the Gapminder [5] data which is found in the gapminder packages in R and python.
library(gapminder)
library(ggplot2)
library(dplyr)
gapminder %>%
filter(year %in% c(1982, 2007)) %>%
filter(country %in% c("Korea, Rep.", "China", "Afghanistan", "India")) %>%
ggplot(aes(x = country, y = lifeExp, fill = factor(year))) +
geom_col(position = "dodge") +
coord_flip() +
ylab("Life Expectancy")
gapminder %>%
filter(year %in% c(1982, 2007)) %>%
filter(country %in% c("Korea, Rep.", "China", "Afghanistan", "India")) %>%
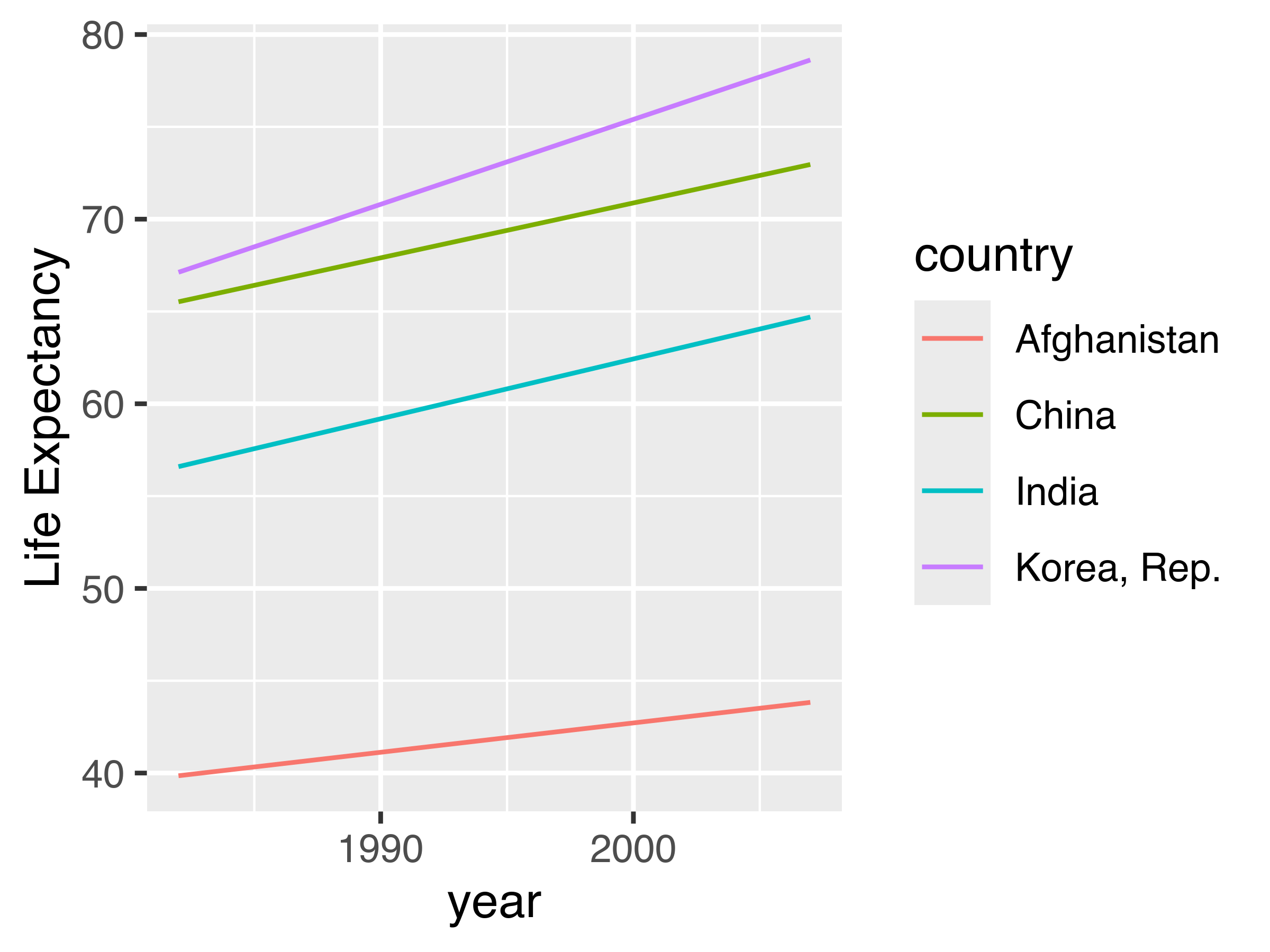
ggplot(aes(x = year, y = lifeExp, color = country)) +
geom_line() +
ylab("Life Expectancy")
gapminder |>
filter(year %in% c(1982, 2007)) |>
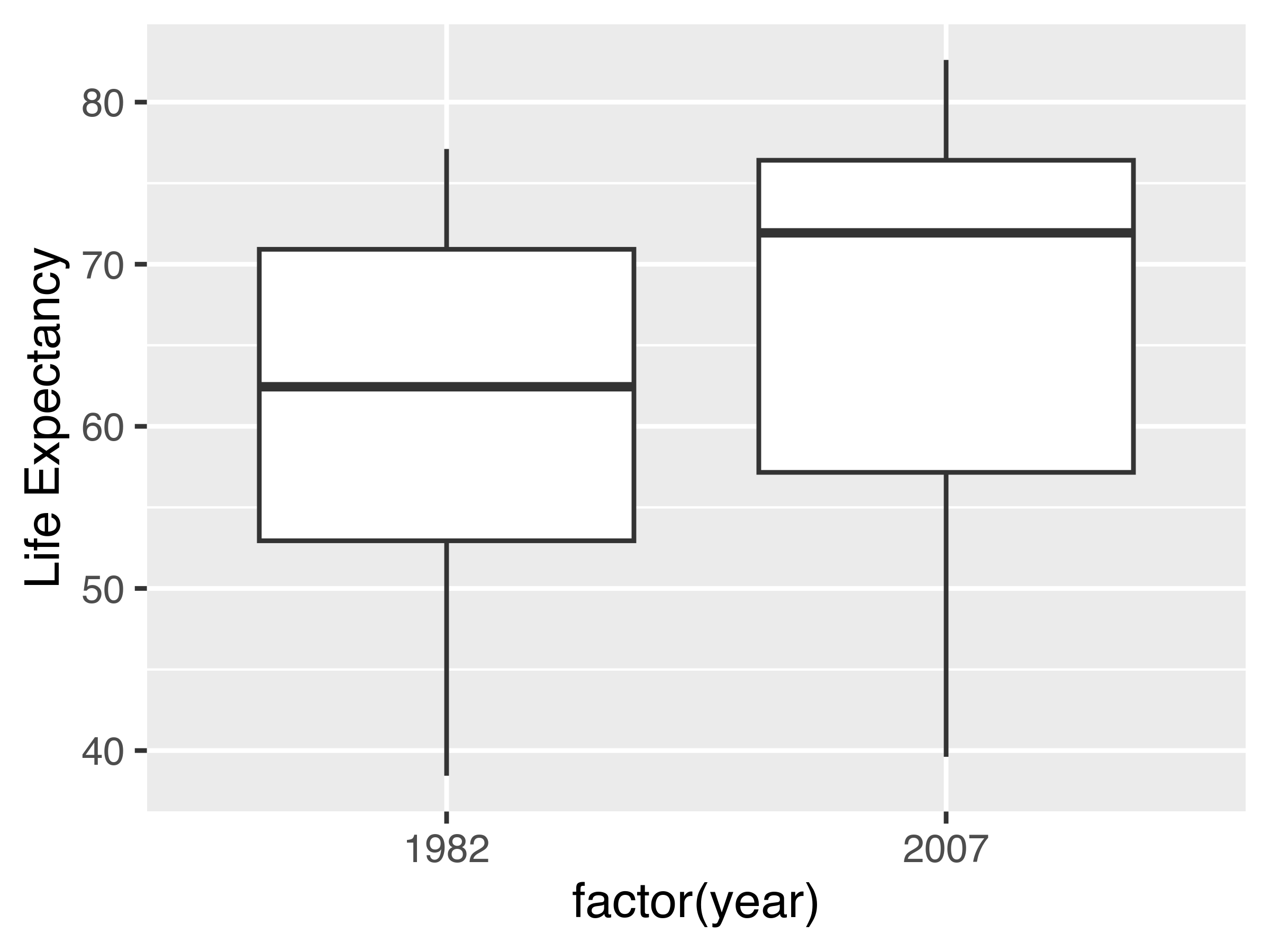
ggplot(aes(x = factor(year), y = lifeExp)) +
geom_boxplot() +
ylab("Life Expectancy")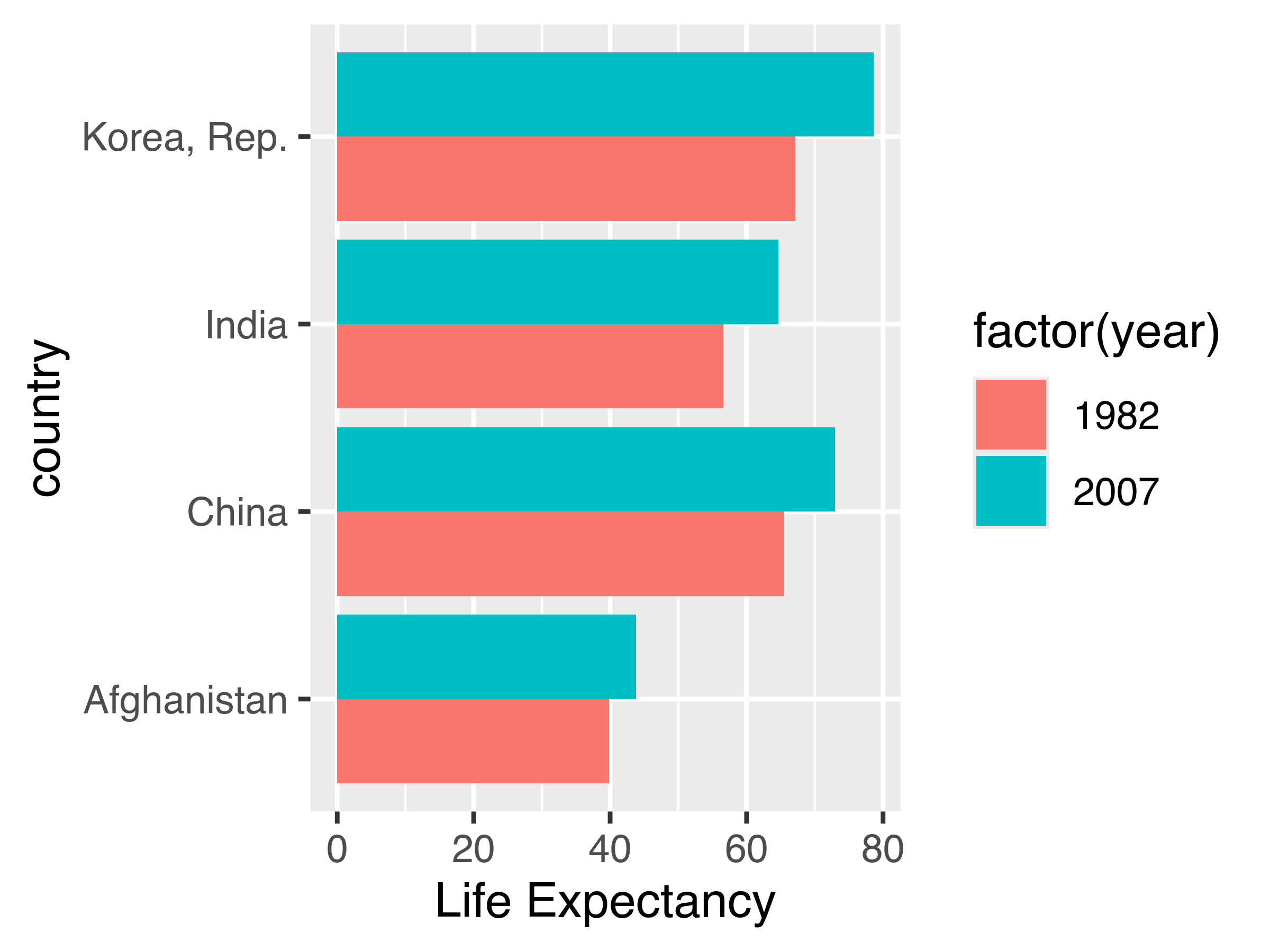
# %pip install gapminder
from gapminder import gapminder
import pandas as pd
import seaborn as sns
import seaborn.objects as so
import matplotlib.pyplot as plt # to clear plots
my_gap = gapminder.query('year.isin([1982,2007])')
my_gap = my_gap.query('country.isin(["Korea, Rep.", "China", "Afghanistan", "India"])')
my_gap = my_gap.assign(yearFactor=pd.Categorical(my_gap.year))
plot = so.Plot(my_gap, x = "country", y = "lifeExp", color = "yearFactor").\
add(so.Bar(), so.Dodge()).\
label(y = "Life Expectancy")
plot.show()
plt.clf() # Clear plot workspace
plot = so.Plot(my_gap, x = "year", y = "lifeExp", color = "country").\
add(so.Lines()).\
label(y = "Life Expectancy")
plot.show()
plt.clf() # Clear plot workspace
sns.boxplot(data = my_gap, x = "year", y = "lifeExp")
plt.show()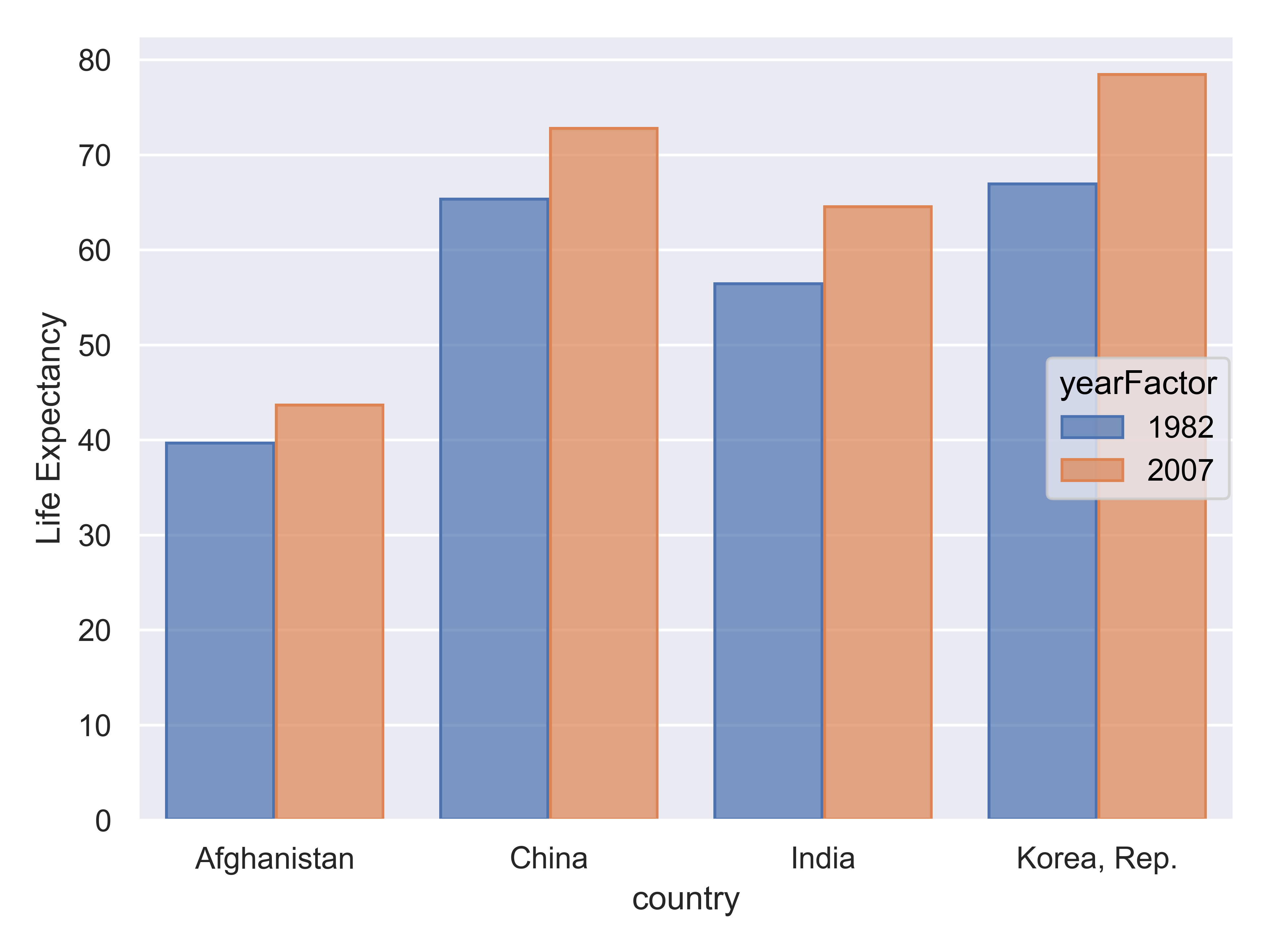
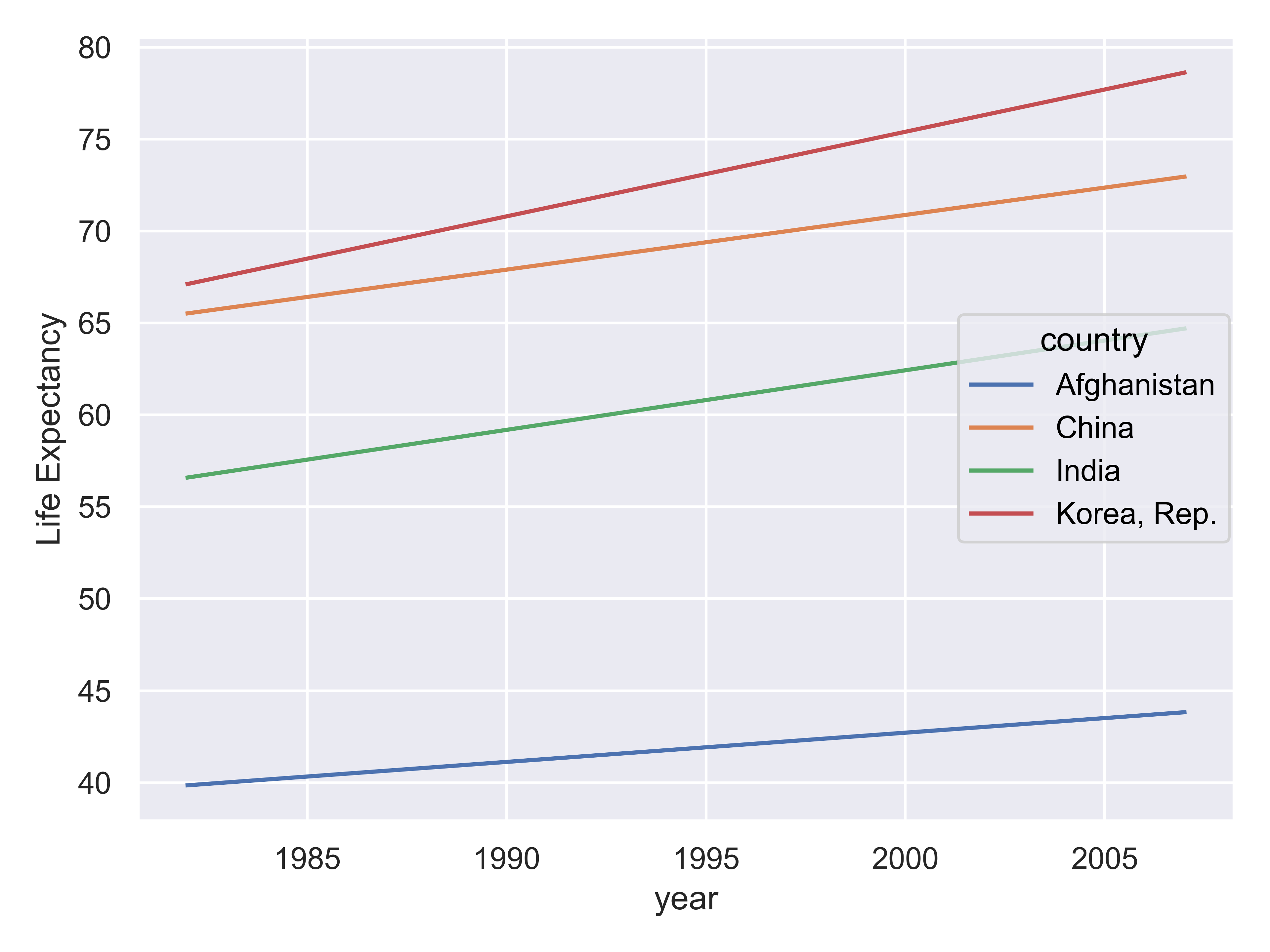
If the goal is to emphasize that every single country had an increase in life expectancy over the period, the best chart is the line chart - we can see upward slopes for each country leading to the conclusion that life expectancy increased. This leverages the Gestalt principles of “similarity” and “common fate”. Similarity, in that all lines point in the same direction, and common fate (often used for motion, e.g. a flock of birds are a group because they move together) because the lines are all “moving together”.
We can derive the same information from the bar chart, but we have to work a bit more for it, because we naturally group bars together by country (proximity) and by year (similarity). We have to then notice that the 2007 bar is bigger for each country to come to the same conclusion – this takes a bit more cognitive effort.
We cannot get the specifics from the box plot, because we cannot see individual country data. This is a case where a summary statistic actually destroys the conclusion we might want to draw from the data and leaves us with weaker information - we can see that there is an increase in the minimum, median, and maximum life expectancy, but it is possible to have this and still have a single-country decrease in life expectancy, so we cannot draw the same conclusion from the box plot that we can from the bar or line charts.
The geometric mappings and aesthetic choices you make when creating plots have a huge impact on the conclusions that you (and others) can easily make when examining plots. Choosing the wrong geometry or statistic can obscure the point you want to make using the data, leading your reader to draw a conclusion that is unsupported, less important, or misleading.
On the other hand, using aesthetic mappings to highlight information can ensure that viewers see the important information you’re trying to communicate 3, and can even tilt the balance when two equally valid conclusions are present in a chart. This power should be used responsibly.
When creating a visualization that involves many different (usually categorical) variables, it is important to decide which variable is the primary comparison of interest. This variable is the one which should be shown in the most easily comparable way – usually, directly on the same plot.
Let’s look at the palmerpenguins data. We have several categorical variables: species, island, year (technically numerical, but there are only 3 years), and sex. The most interesting part of this data set is how the morphology (measurements) of penguins changes based on their sex and species, so let’s explore what different charts examining bill_len and body_mass might look like across those variables. For this example, I’ll drop penguins with an unidentified sex for visual simplicity.
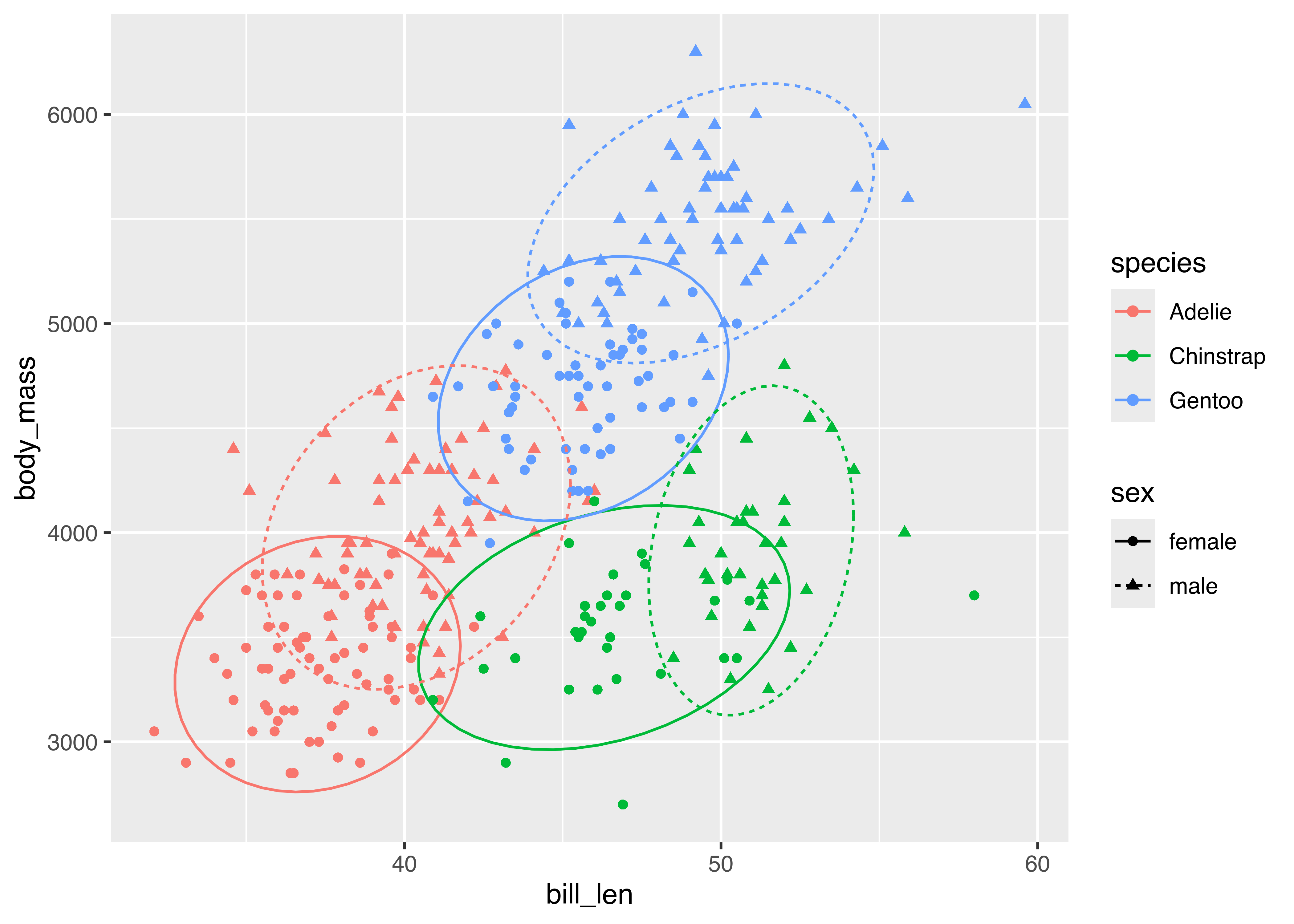
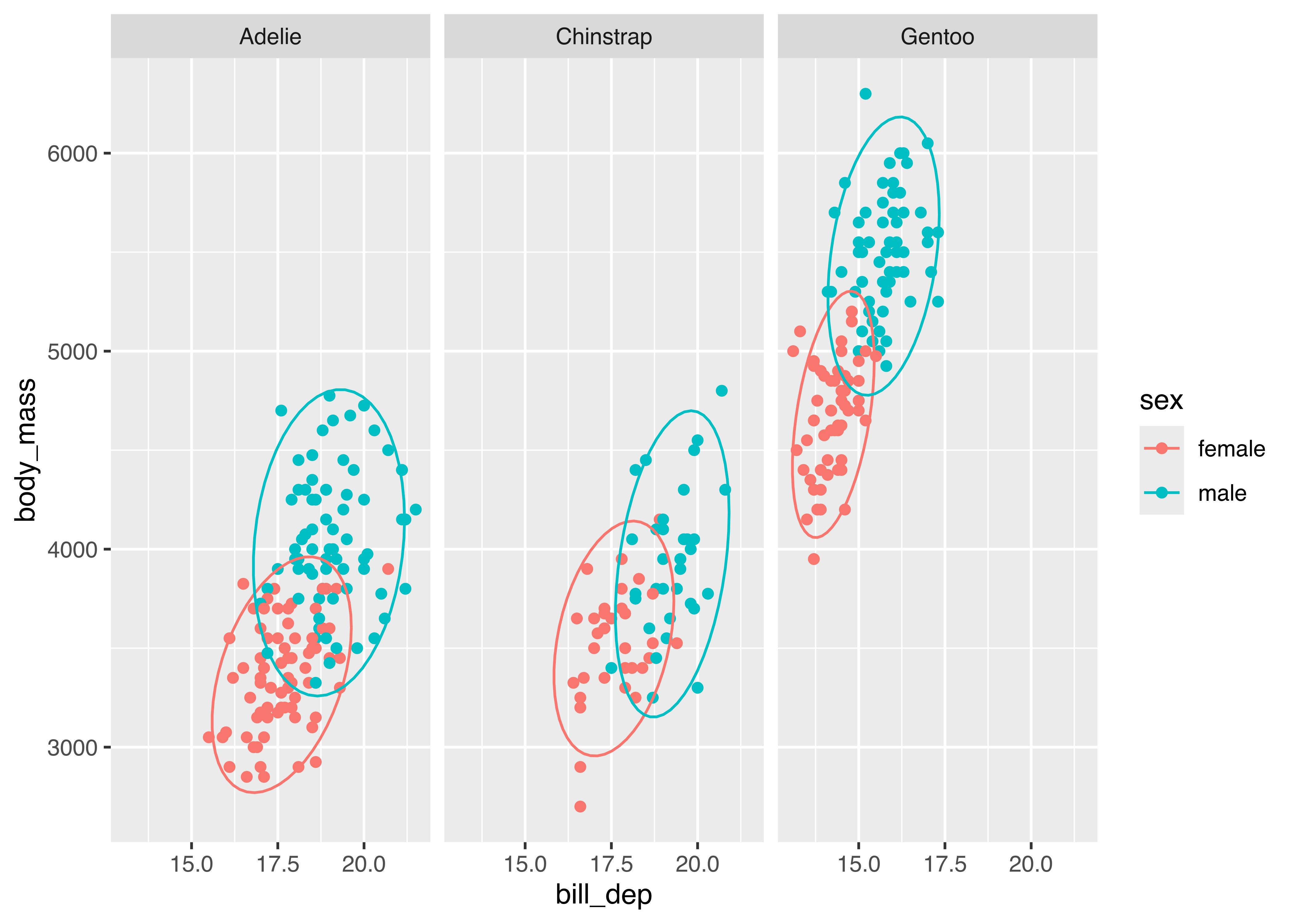
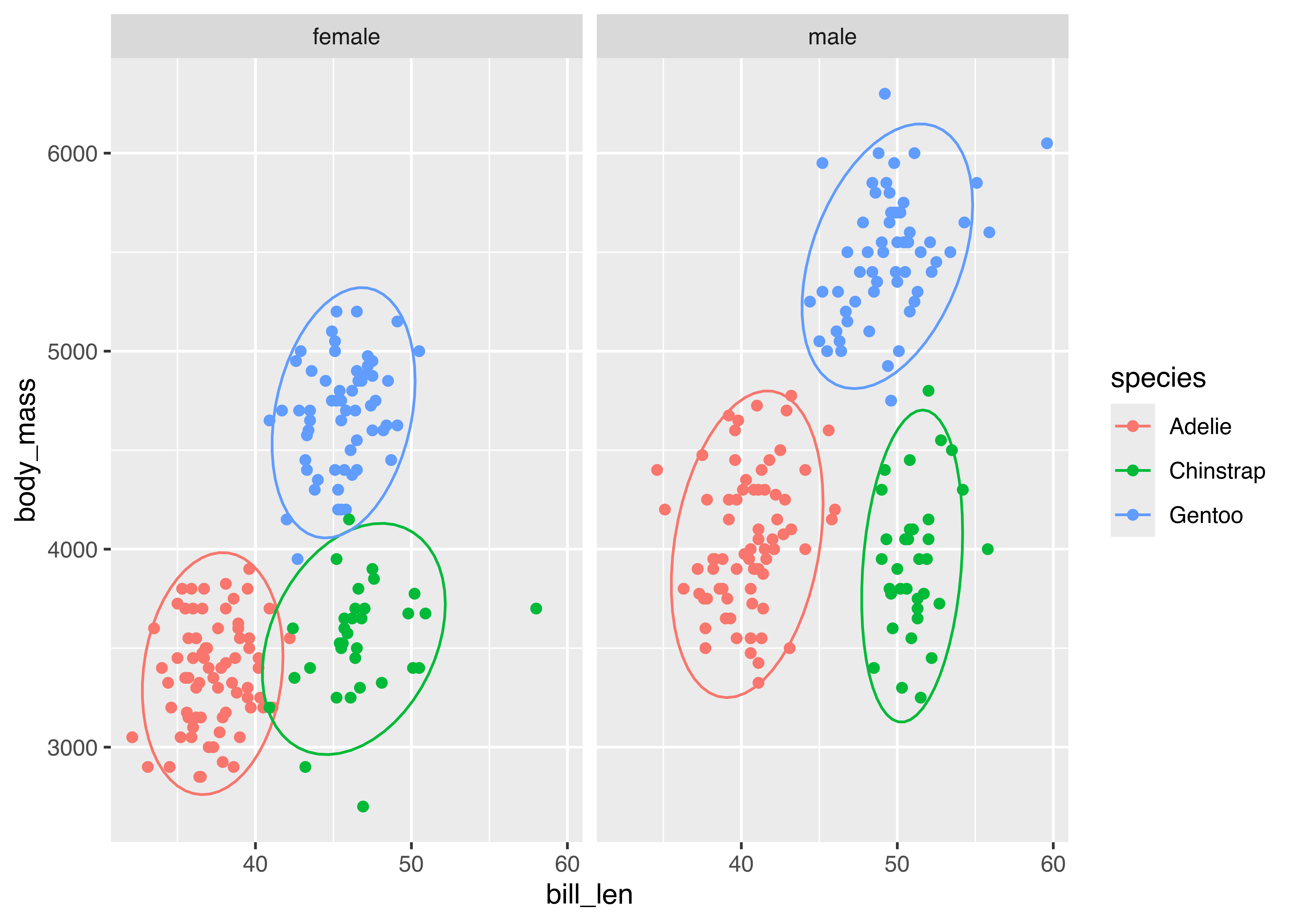
palmerpenguins data comparing bill_len and body_mass across sex and species. Click on figures to enlarge.
Which plot makes it easier to answer the following questions:
Different aesthetic mappings and facets can lead to different overall conclusions from the same data. It is important when you are exploring data to generate many different plots, so that you get a more comprehensive picture of your data. When you want to explain the data to others, it is equally important to carefully choose the most important findings from the data and present charts that back up those findings.
In order to read data off of a chart correctly, several things must happen in sequence:
If step 1 is not done correctly, the chart is misleading or inaccurate. However, steps 2 and 3 depend on our brains accurately perceiving and estimating information mentally. These steps can involve a lot of effort, and as mental effort increases, we tend to take shortcuts. Sometimes, these shortcuts work well, but not always.
When you design a chart, it’s good to consider what mental tasks viewers of your chart need to perform. Then, ask yourself whether there is an equivalent way to represent the data that requires fewer mental operations, or a different representation that requires easier mental calculations.
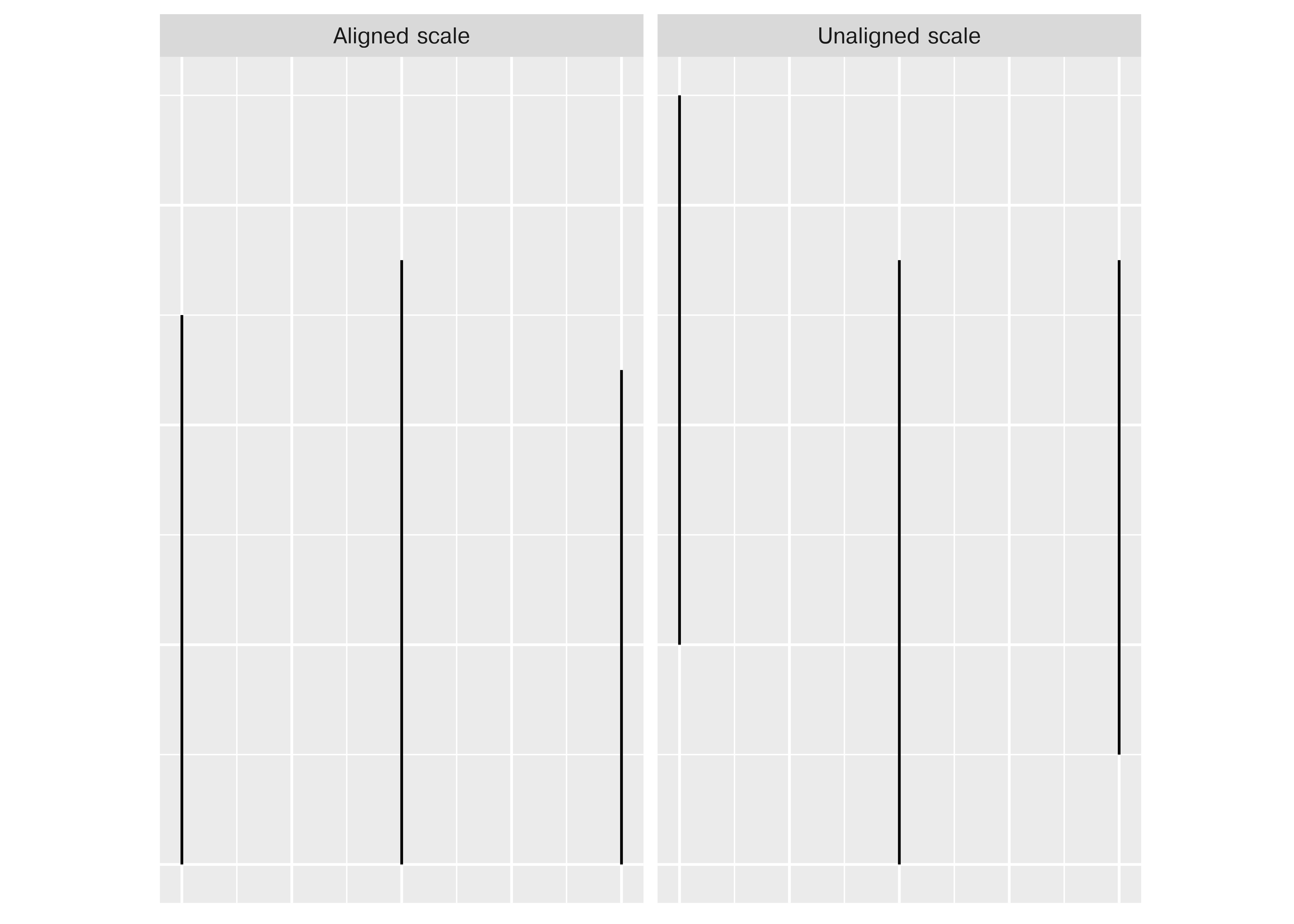
When making judgments corresponding to numerical quantities, there is an order of tasks from easiest (1) to hardest (6), with equivalent tasks at the same level. See this paper for the major source of this ranking; other follow-up studies have been integrated, but the essential order is largely unchanged.
If we compare a pie chart and a stacked bar chart, the bar chart asks readers to make judgments of position on a non-aligned scale, while a pie chart asks readers to assess angle. This is one reason why pie charts tend not to be a good general option – people must compare values using area or angle instead of position or length, which is a more difficult judgment under most circumstances. When there are a limited number of categories (2-4) and you have data that is easily compared to quarters of a circle, it may be justifiable to use a pie chart over a stacked bar chart - some studies have shown that pie charts are preferable under these conditions. As a general rule, though, we have an easier time comparing position than angle or area.
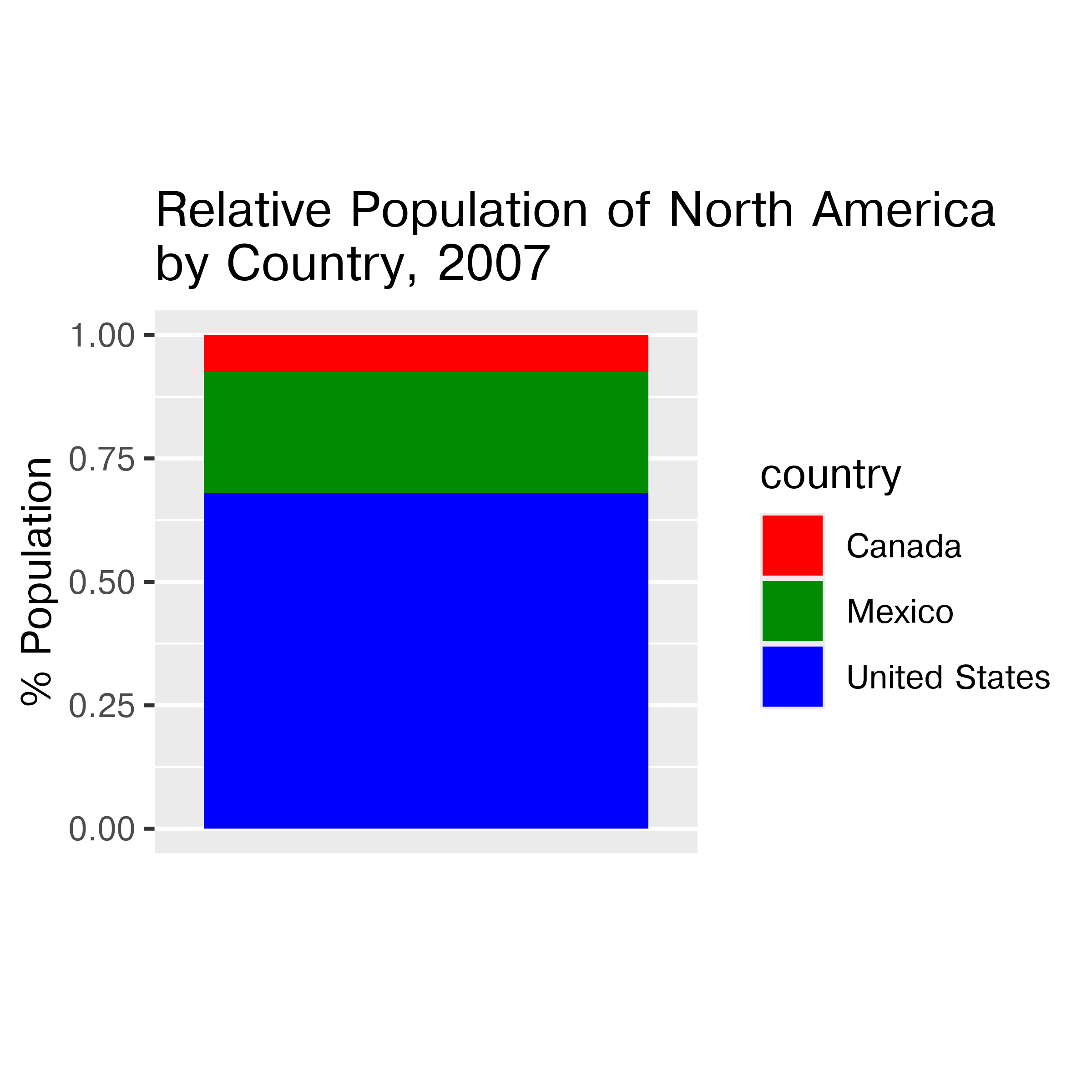
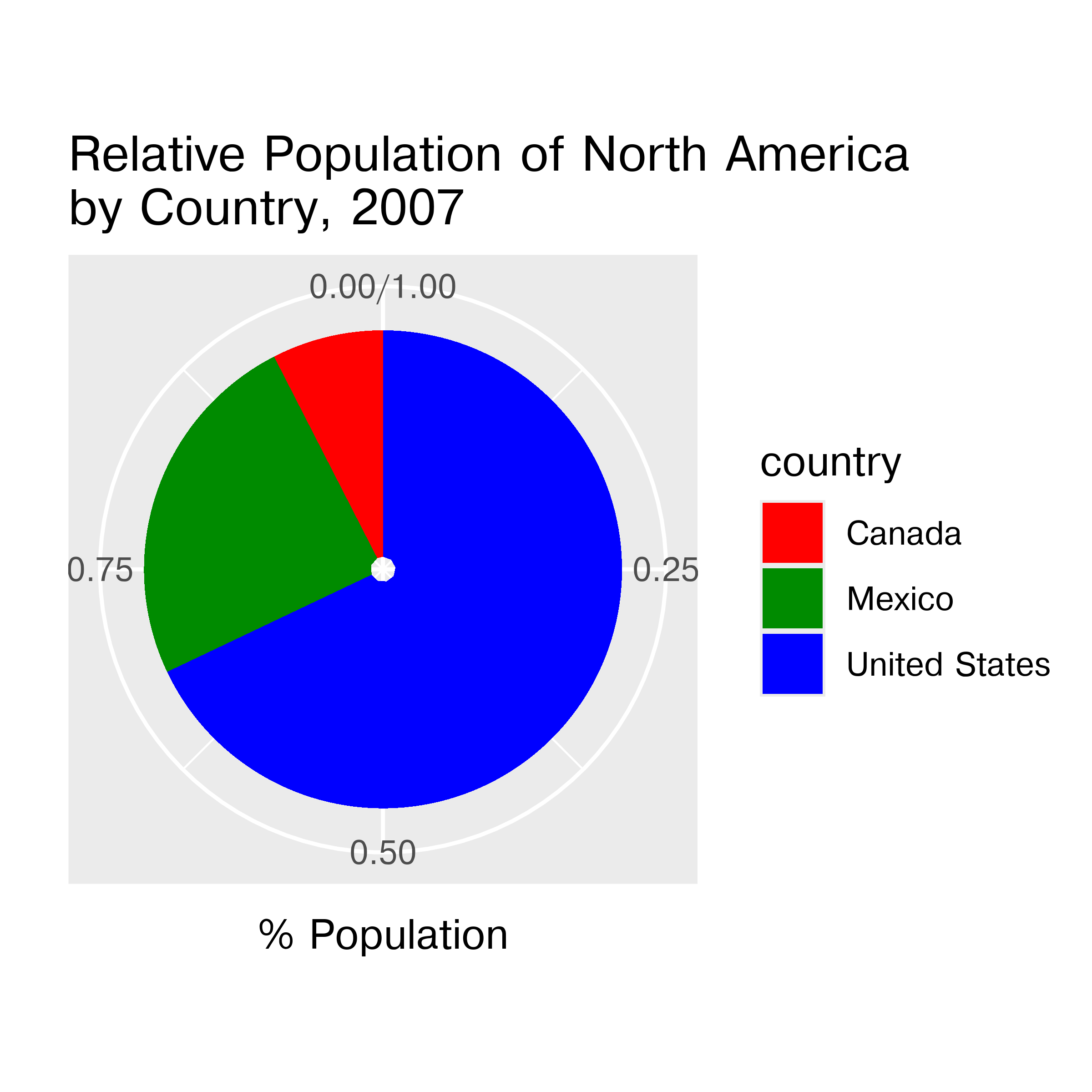
Stacked bar and pie charts showing the relative proportion of people in North America living in the US, Canada, and Mexico in 2007. Which chart is easier to read relative information (e.g. there are about 3x as many people living in Mexico as Canada) from? Which chart is easier to estimate raw proportions (e.g. the US makes up about 70% of the population of North America) from?
When creating a chart, it is helpful to consider which variables you want to show, and how accurate reader perception needs to be to get useful information from the chart. In many cases, less is more - you can easily overload someone, which may keep them from engaging with your chart at all [6]. Variables which require the reader to notice small changes should be shown on position scales (x, y) rather than using color, alpha blending, etc.
Consider the hierarchy of graphical tasks again.
You may notice a general increase in dimensionality from 1-3 to 4 (2d) to 5 (3d). In general, showing information in 3 dimensions when 2 will suffice can be misleading. Just how misleading depends a lot on the type of chart you’re using. Most of the time, the addition of an extra dimension causes an increase in chart area allocated to the item that is disproportionate to the actual numerical value being represented.
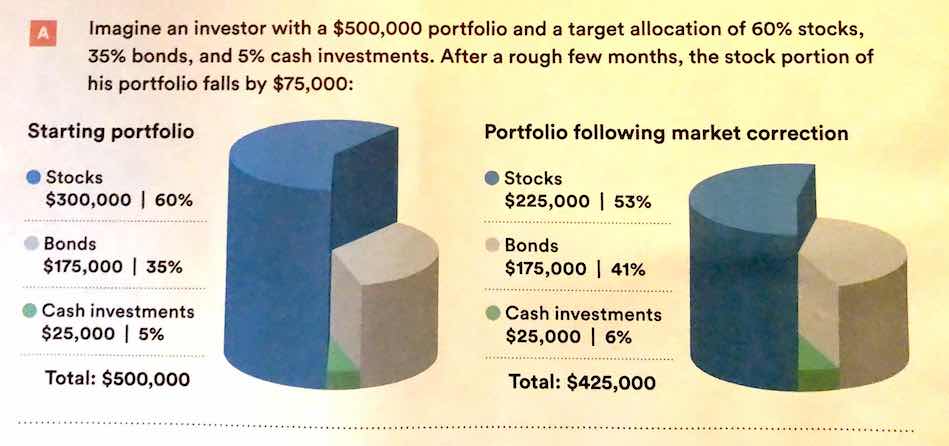
Extra dimensions and other annotations are sometimes called “chartjunk” and should only be used if they contribute to the overall numerical accuracy of the chart (e.g. they should not just be for decoration).
This section is inspired by Chapter 8 of Getting More out of Graphics by Antony Unwin. We’ll work with the FIDE (International Chess Federation) data, which ranks individual chess players using all official games. The Chess2020 object from the ChessGmooG data package created to accompany Getting More out of Graphics contains the rankings from December 2020.
First, we need to do a bit of data setup so that both R and Python can access the data. This time, it’s critical to run the R code first and then python, since we’re exporting the data from R to a CSV that can be read in using python.
## packages for the chapter
# install.packages(c("ggridges", "ChessGmooG"))
library(ChessGmooG)
data(Chess2020)
readr::write_csv(Chess2020, file = "../data/Chess2020.csv")import pandas as pd
import numpy as np
Chess2020 = pd.read_csv("../data/Chess2020.csv")First, it’s a good idea to generate some basic distributional plots to explore the contents of the data.
library(ggplot2)
theme_set(theme_bw())
library(dplyr)
ggplot(Chess2020, aes(x = DEC20)) +
geom_histogram(binwidth = 10) +
xlab("Rating") + ylab("# Players")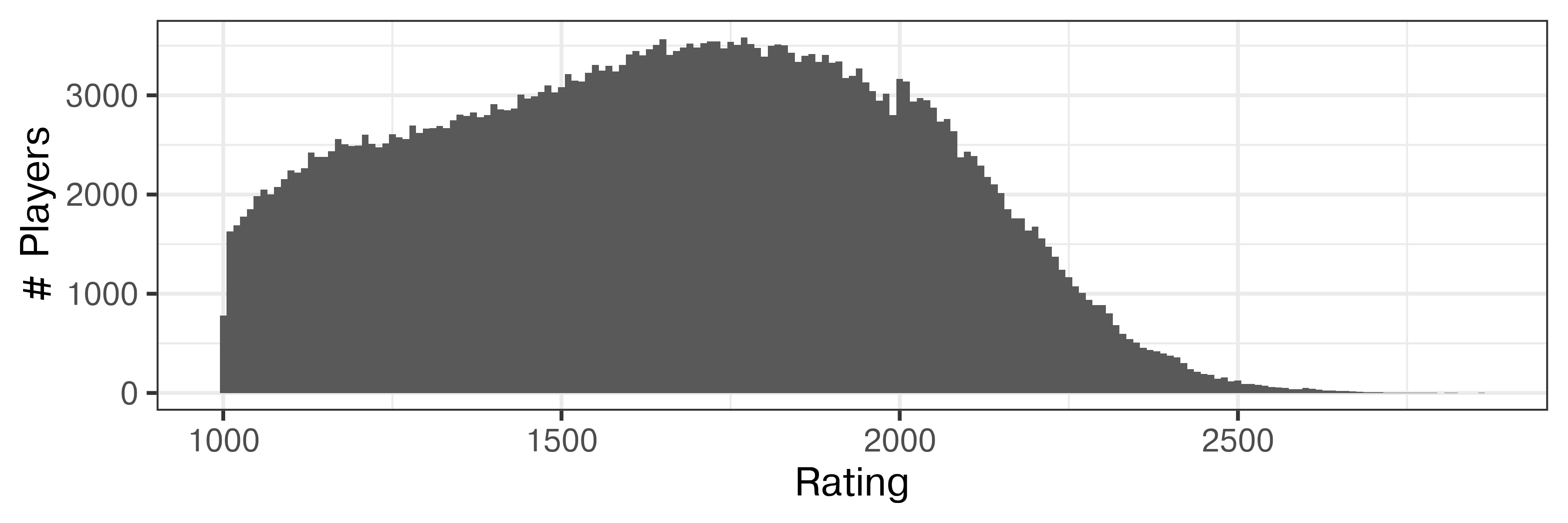
import seaborn.objects as so
import seaborn as sns
import matplotlib.pyplot as plt # Set figure size
plt.figure(figsize=(6,2))
so.Plot(Chess2020, x = "DEC20").add(so.Bars(), so.Hist(binwidth=10)).label(x = "Rating", y = "# Players").show()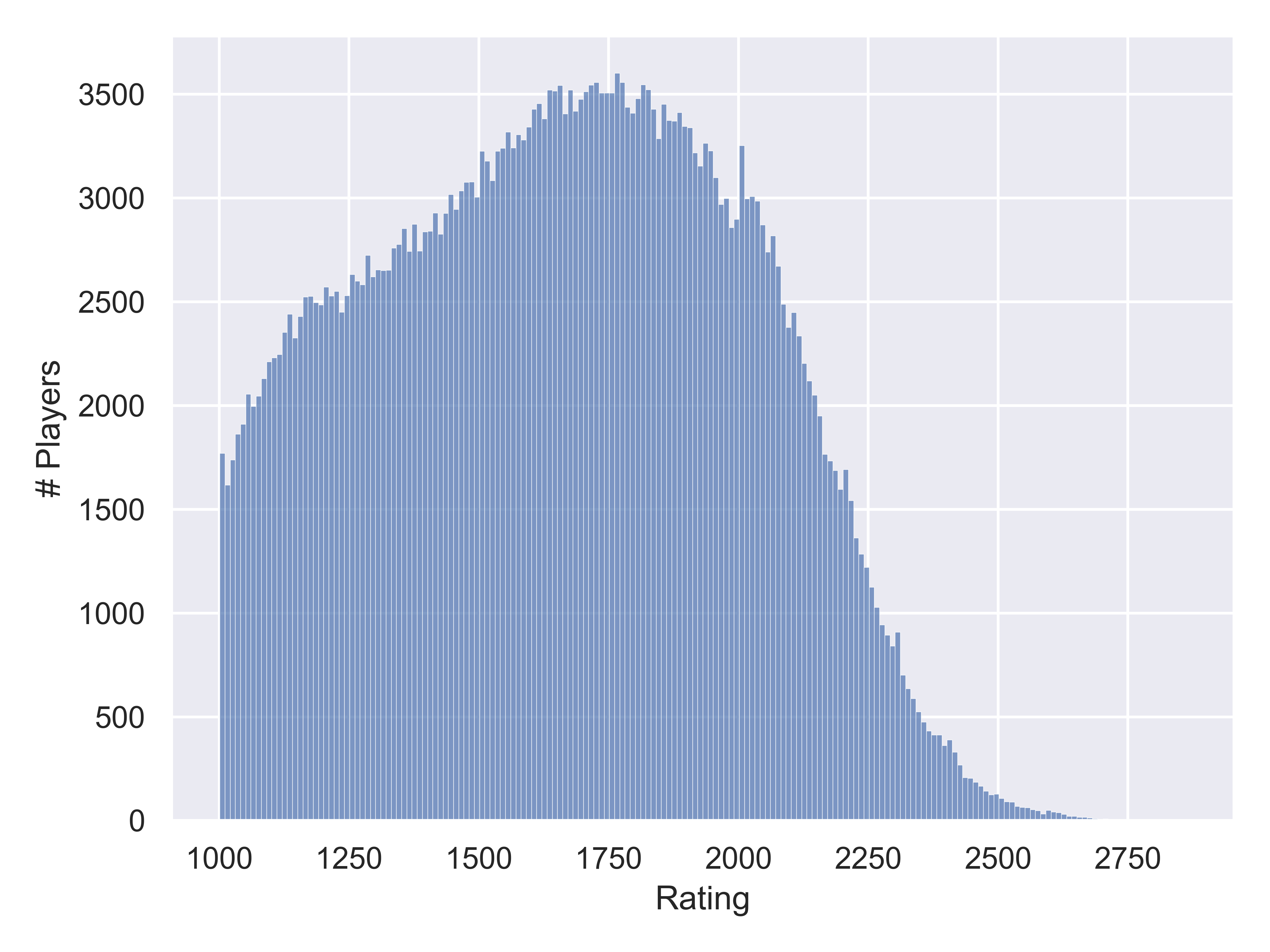

The data only includes players whose rating is above 1000, which explains the sharp drop-off on the left edge of the distribution. There are slight hints of bumps in the distribution at about 1200 and at the max of about 1750. Other features include the slight spike at 2000, an additional very narrow bump just after 2000, and the long tail after that point.
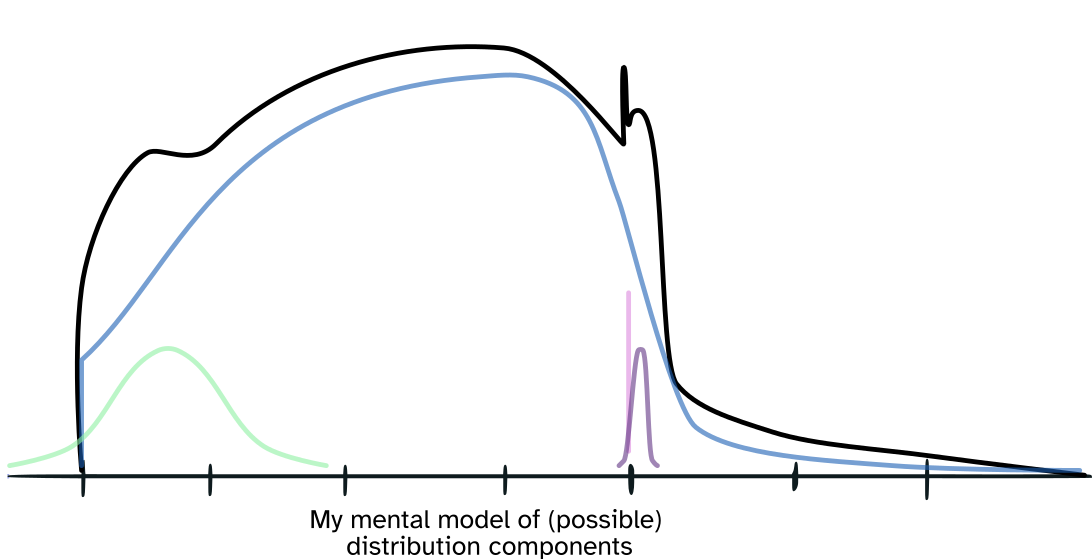
What if the different curves are due to activity? We have active and inactive players, and we might find that some of the distribution’s features are activity related.
Chess2020 <- Chess2020 |>
mutate(Activity = if_else(Flag %in% c("wi", "i"), "Inactive", "Active"))
ggplot(Chess2020, aes(x = DEC20)) +
geom_histogram(binwidth = 10) +
xlab("Rating") + ylab("# Players") +
facet_grid(~Activity)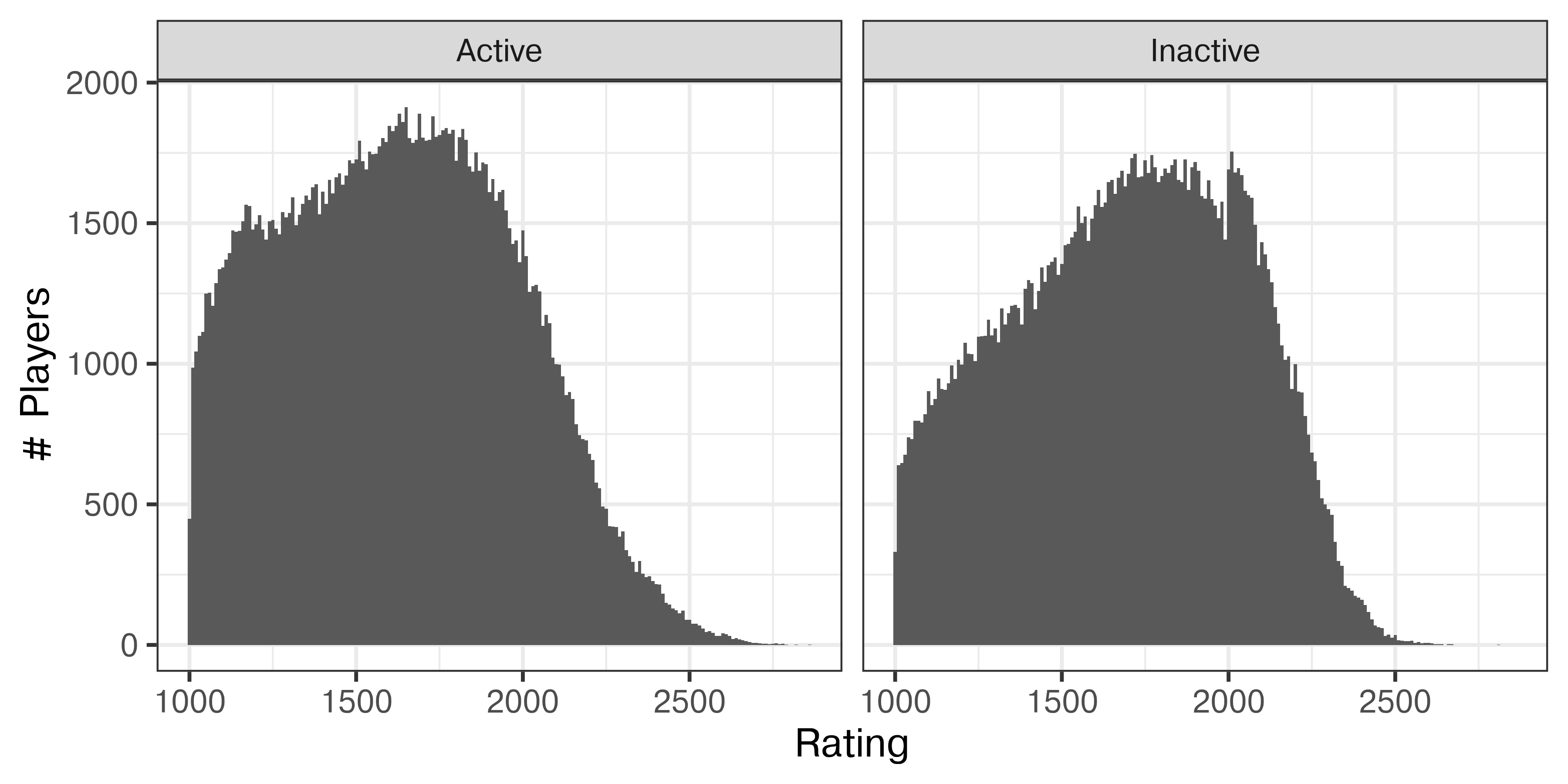
plt.figure(figsize=(6,3))
Chess2020['Activity'] = Chess2020.Flag.replace(to_replace={"i":"Inactive", "wi": "Inactive", "w": "Active"})
Chess2020 = Chess2020.fillna({"Activity":"Active"})
so.Plot(Chess2020, x = "DEC20").add(so.Bars(), so.Hist(binwidth=10)).facet(col="Activity").label(x = "Rating", y = "# Players").show()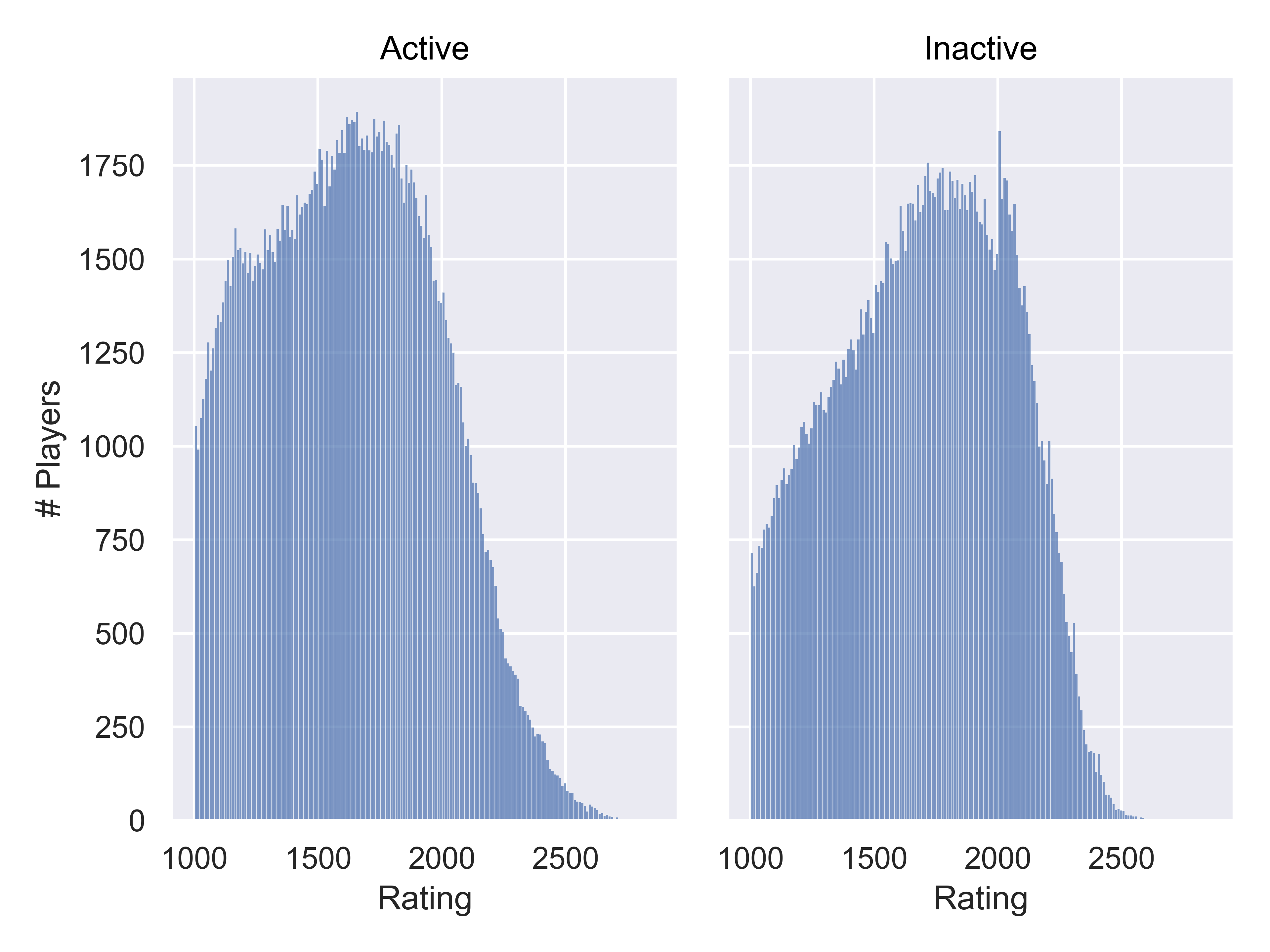

The left “bump” only occurs in Active players, and the right “bump” becomes much more clearly a one-sided peak at 2000, and only occurs in Inactive players. It seems likely that players are more likely to become inactive once they reach their perceived peak, and for many players that occurs at 2000.
Chess2020 <- Chess2020 |>
mutate(Bday = as.numeric(Bday),
Age = 2020 - Bday,
Age = if_else(Age == 2020, NA, Age))
mean(is.na(Chess2020$Age)) # Only missing age for about 2.4% of players
## [1] 0.02367435
Chess2020 |>
filter(Activity == "Active") |>
ggplot(aes(x =Age, y = DEC20)) +
geom_point(alpha = 0.01) +
geom_smooth() +
xlab("Age in 2020") + ylab("Rating") +
scale_x_continuous(breaks = (1:10)*10)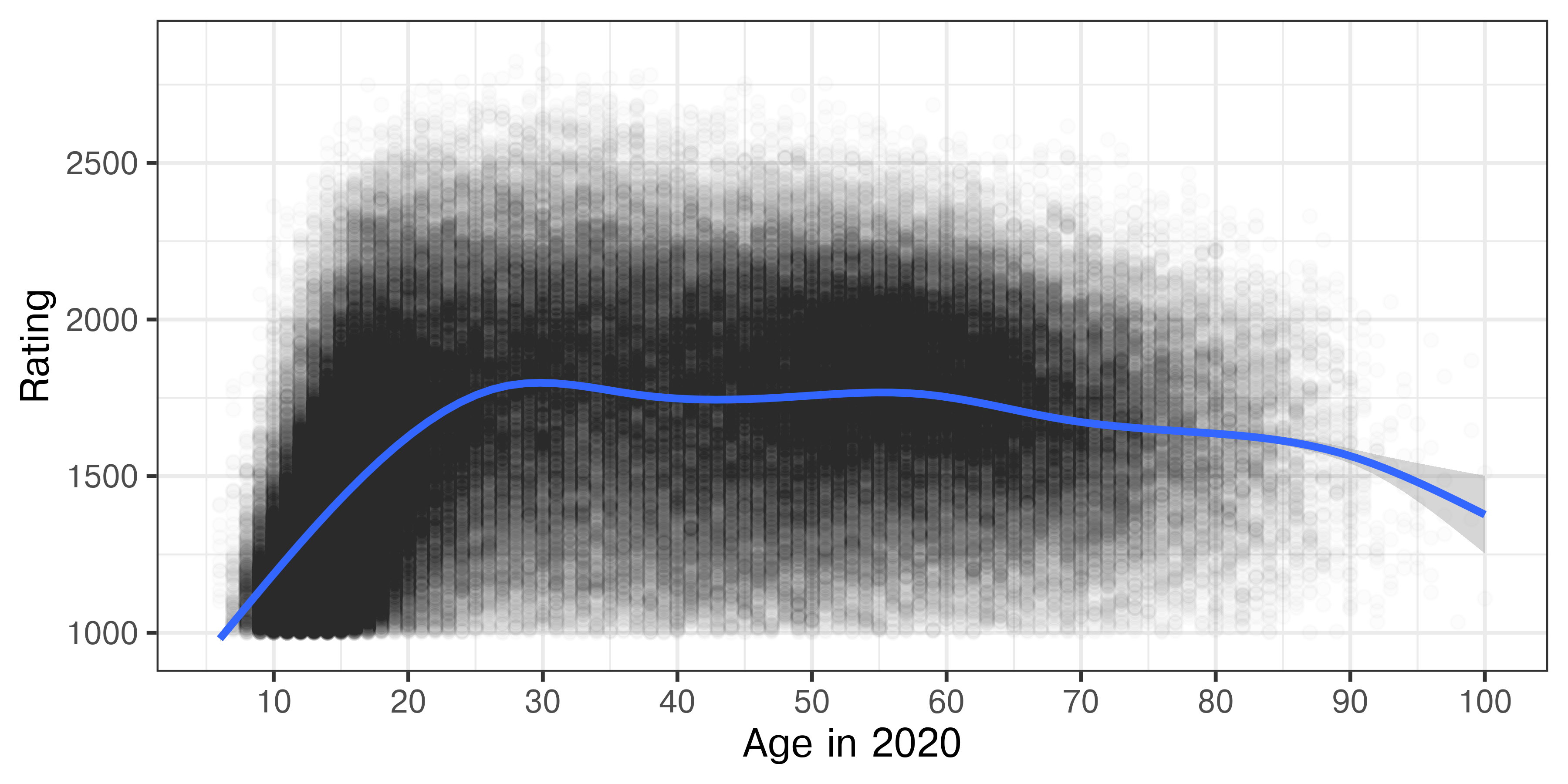
#%pip install seaborn_objects_recipes
import seaborn_objects_recipes as sor
Chess2020['Bday'] = pd.to_numeric(Chess2020.Bday)
Chess2020['Age'] = 2020-Chess2020.Bday
Chess2020[Chess2020.Age==2020] = pd.NA
Chess2020.Age.isna().mean() # Only missing age for about 2.4% of players
## np.float64(0.023674352141505425)
active2020 = Chess2020.query('Activity=="Active"')
(
so.Plot(active2020, x = 'Age', y = "DEC20").
add(so.Dot(color='black', alpha=.002)).
add(so.Line(), lowess:= sor.Lowess(frac=0.1, gridsize=1000)).
label(x = "Age in 2020", y = "Rating").
scale(x = so.Continuous().tick(every=10)).
show()
)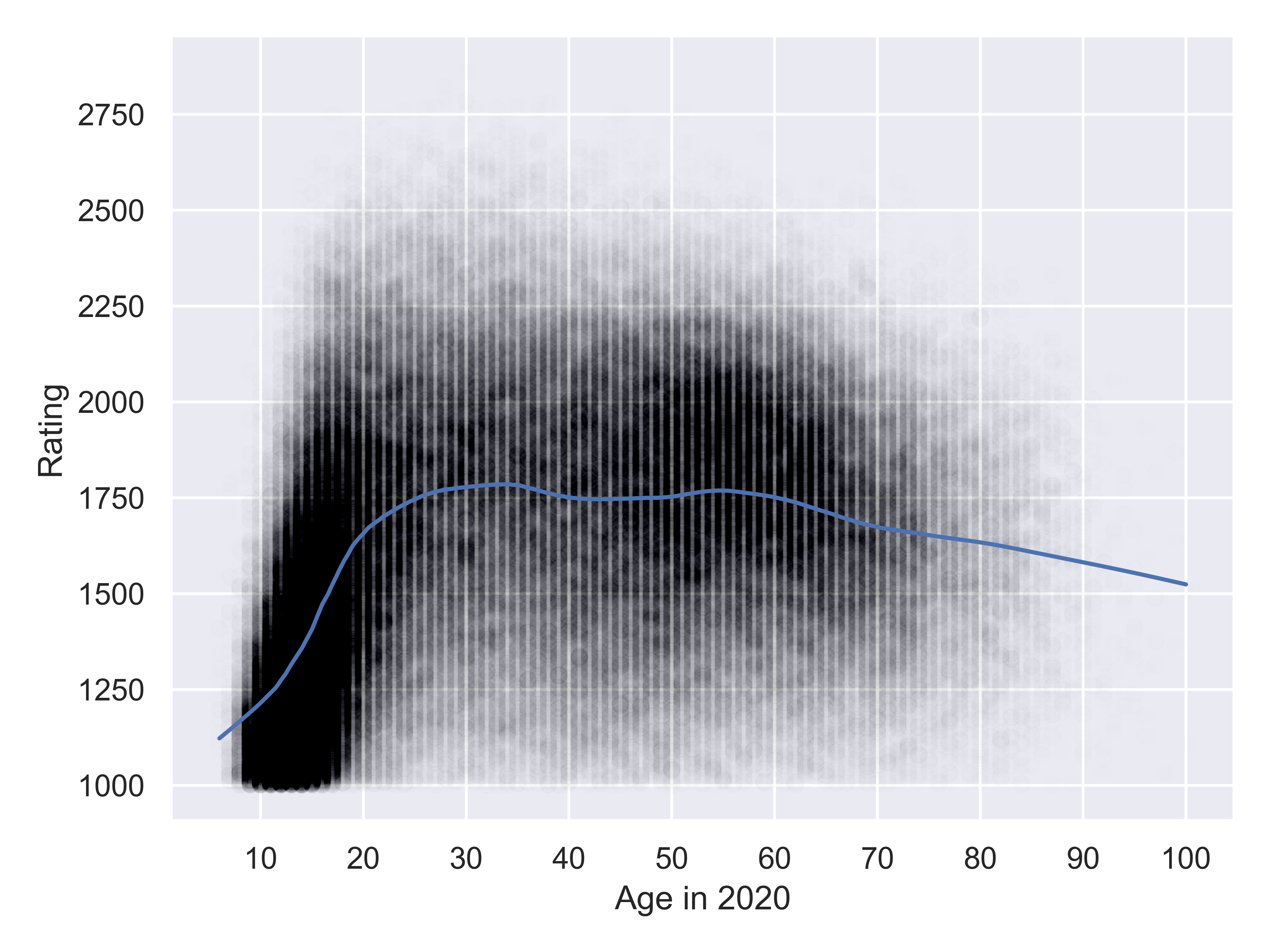
It appears that players can start getting ratings of \(> 1000\) around 8 or 9, at which point they get included in the data. Their rating increases steeply as they age, up to about 20 years old, at which point there is a much more gradual increase to age 30. After that, performance stays steady until age 60 and begins to decline.
However, it seems likely that there are some drop-out effects here, as we are only looking at active players, and the number of e.g. 20 year olds playing may decrease from the number of e.g. 16 year olds playing.
Show the Data
Notice the utility here of showing the whole data set and then highlighting a trend - we’re not really hiding anything from the viewer, so they can still see the messiness, but we’ve chosen alpha carefully to try to balance density and overplotting with being able to see the points at all. Then, we highlight the overall trend with a line that stands out from the black-and-white plot.
When you have too much data, it can be challenging to figure out the best way to represent it. Some options:
Additionally, when you have overplotting but not too much data, it can be helpful to try geom_jitter to move similar values into a point cloud around the value. That won’t help in this situation, but it’s a good trick in general.
The next set of tabs shows these options as executed in ggplot2 (for brevity, I’m not showing python/seaborn here).
Chess2020 |>
filter(Activity == "Active") |>
ggplot(aes(x =Age, y = DEC20)) +
geom_point(shape = 1, alpha = .05) +
geom_smooth() +
xlab("Age in 2020") + ylab("Rating") +
scale_x_continuous(breaks = (1:10)*10) +
ggtitle("Age and Rating")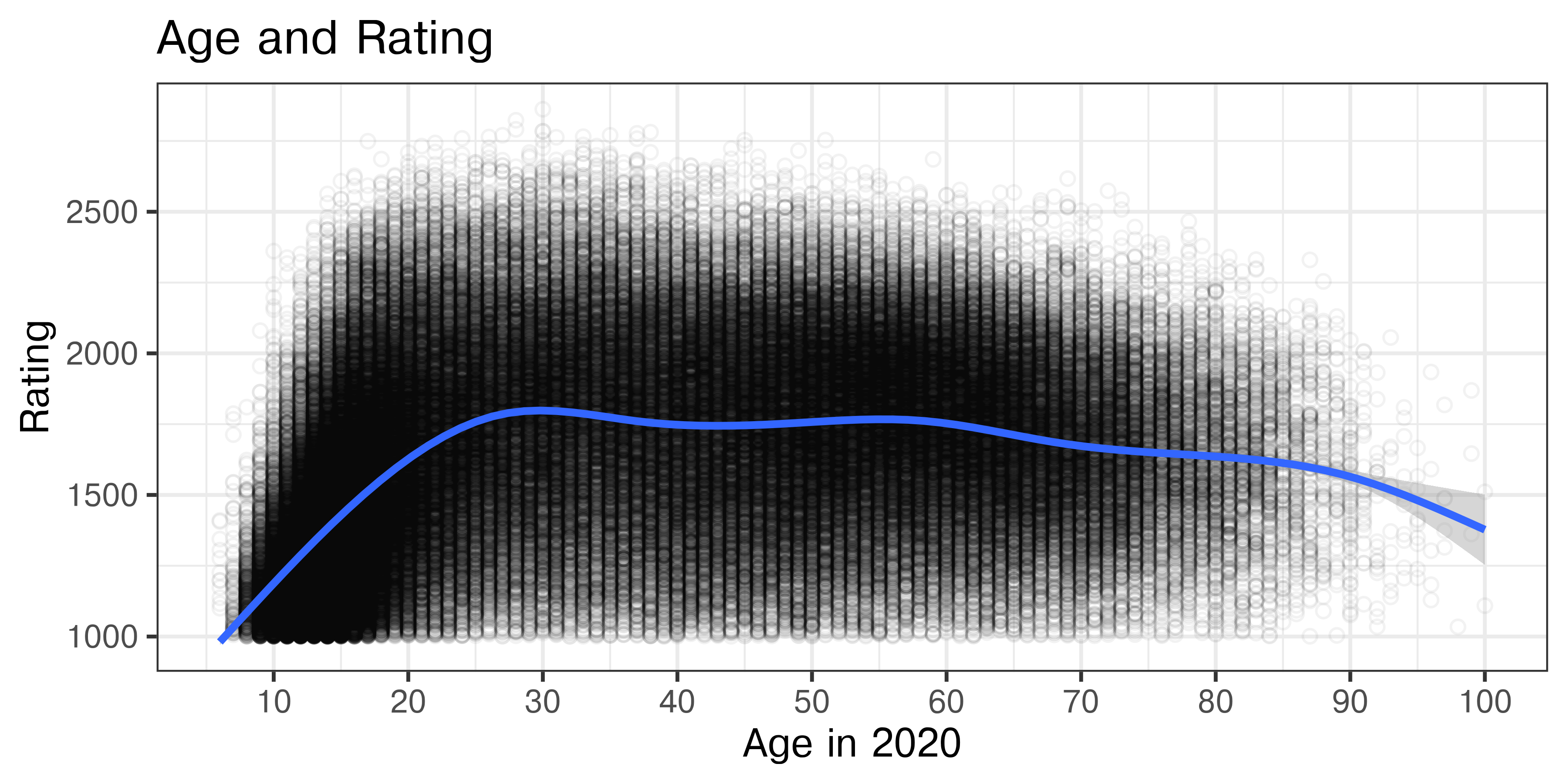
Notice that this gives us somewhat better definition of the density areas than Figure 21.19, and allows us to see that the point density is much higher in the cluster between 10 and 20 than it is between 45 and 70.
Chess2020 |>
filter(Activity == "Active") |>
sample_frac(size = .2, replace = F) |>
ggplot(aes(x =Age, y = DEC20)) +
geom_point(shape = 1, alpha = .25) +
geom_smooth() +
xlab("Age in 2020") + ylab("Rating") +
scale_x_continuous(breaks = (1:10)*10) +
ggtitle("Age and Rating", subtitle = "For a sample of 20% of the active players in the FIDE 2020 data")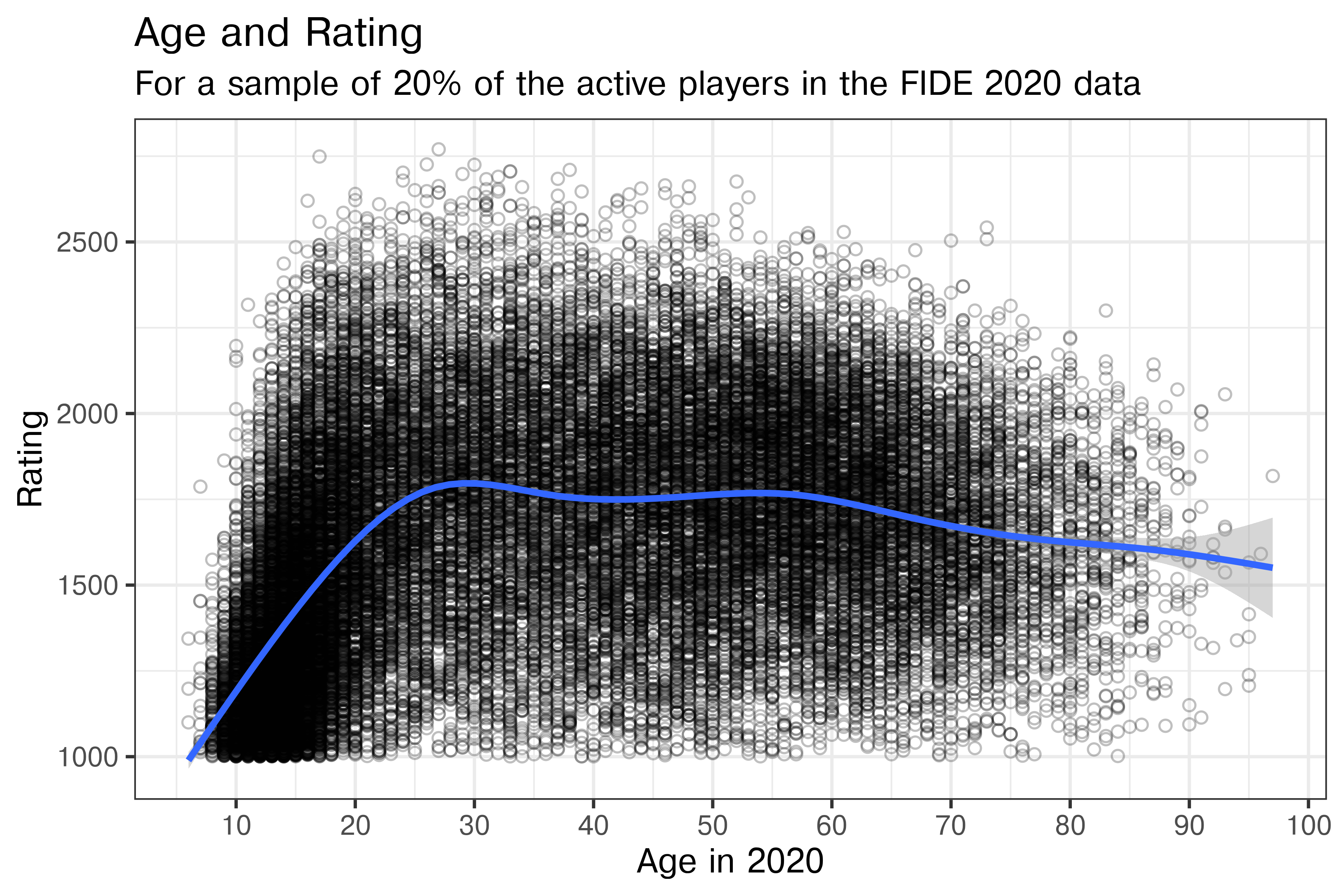
Chess2020 |>
filter(Activity == "Active") |>
ggplot(aes(x =Age, y = DEC20)) +
geom_hex() +
scale_fill_gradient(low = "#E8EBF8", high = "#1432BA", trans="log10") +
geom_smooth(color = "orange") +
xlab("Age in 2020") + ylab("Rating") +
scale_x_continuous(breaks = (1:10)*10) +
ggtitle("Age and Rating")
Chess2020 |>
filter(Activity == "Active") |>
ggplot(aes(x =Age, y = DEC20)) +
geom_bin_2d(binwidth = list(x = 2, y = 100)) +
scale_fill_gradient(low = "#E8EBF8", high = "#1432BA", trans="log10") +
geom_smooth(color = "orange") +
xlab("Age in 2020") + ylab("Rating") +
scale_x_continuous(breaks = (1:10)*10) +
ggtitle("Age and Rating")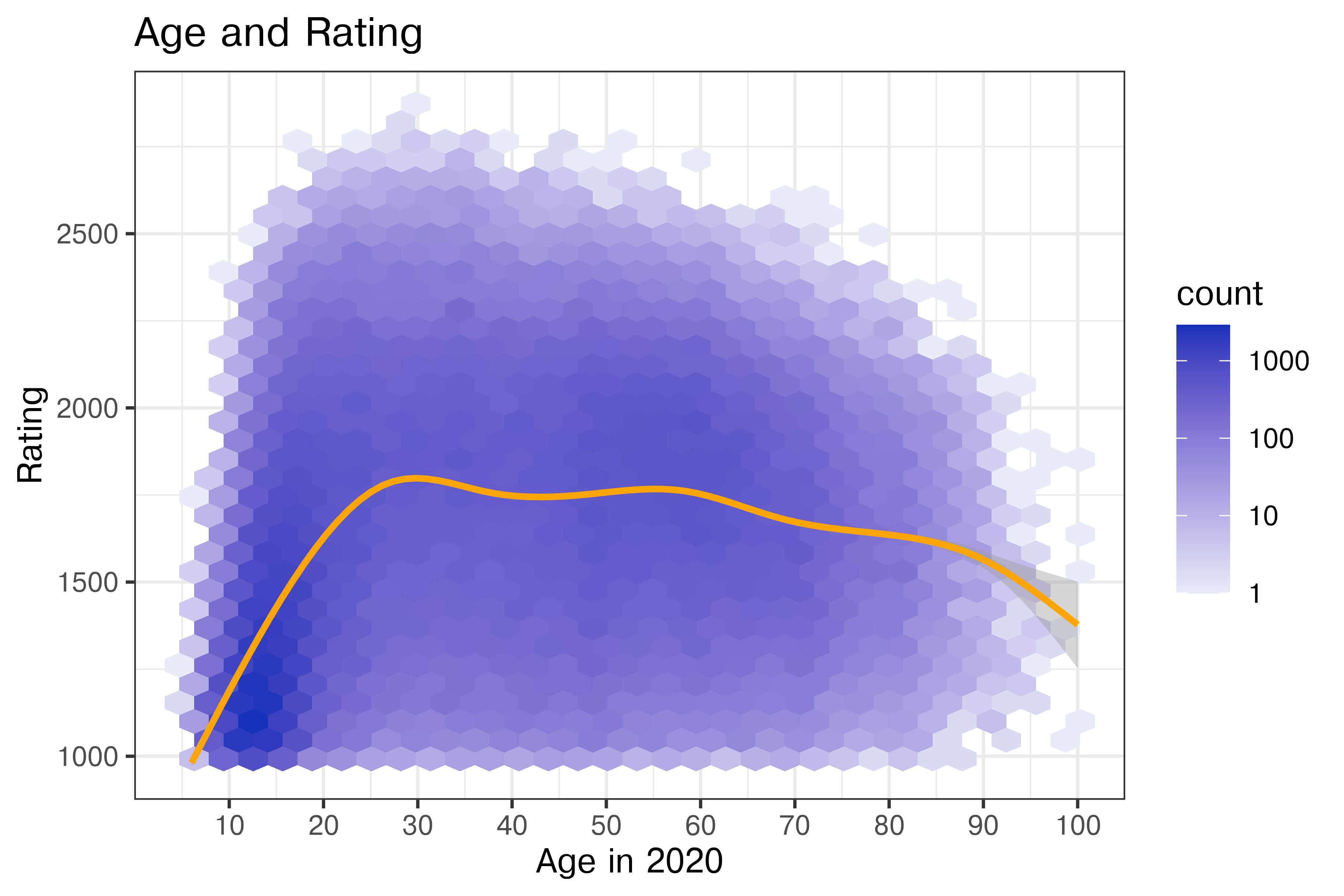
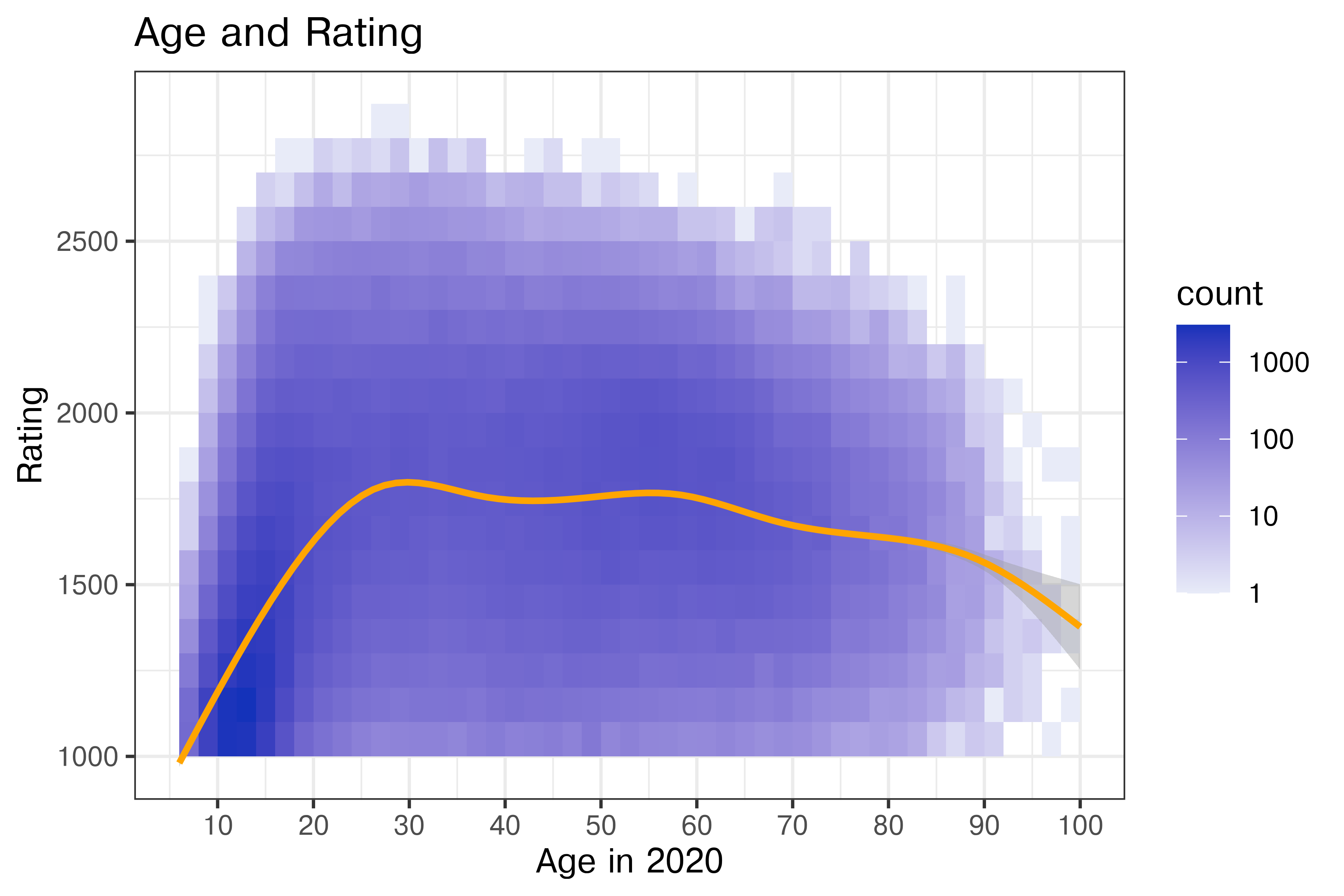
There are several intentional but non-trivial modifications here:
While this is no longer showing the raw data (as we’ve binned and computed a statistic), it’s still reasonably close to the raw data. This is perhaps the first plot where we get a true sense of how many actively playing children there are in chess matches, and how dense they are relative to the distribution of ratings once out of childhood.
Returning to our exploration, let’s consider the age distribution of active vs. inactive players.
Chess2020 |>
# filter(Activity == "Active") |>
ggplot(aes(x = Age, color = Activity)) +
geom_density()+
xlab("Age in 2020") +
scale_x_continuous(breaks = (1:10)*10)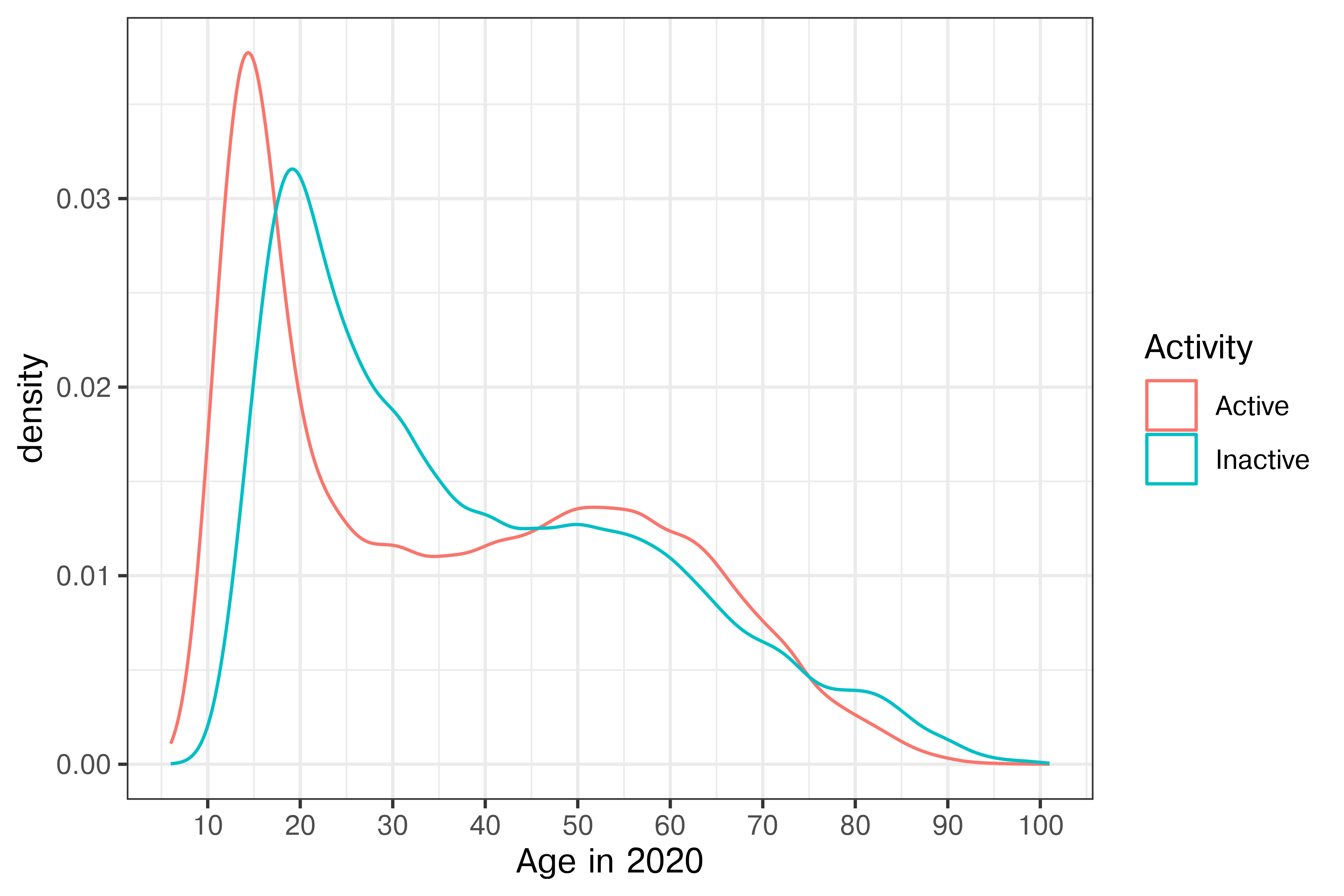
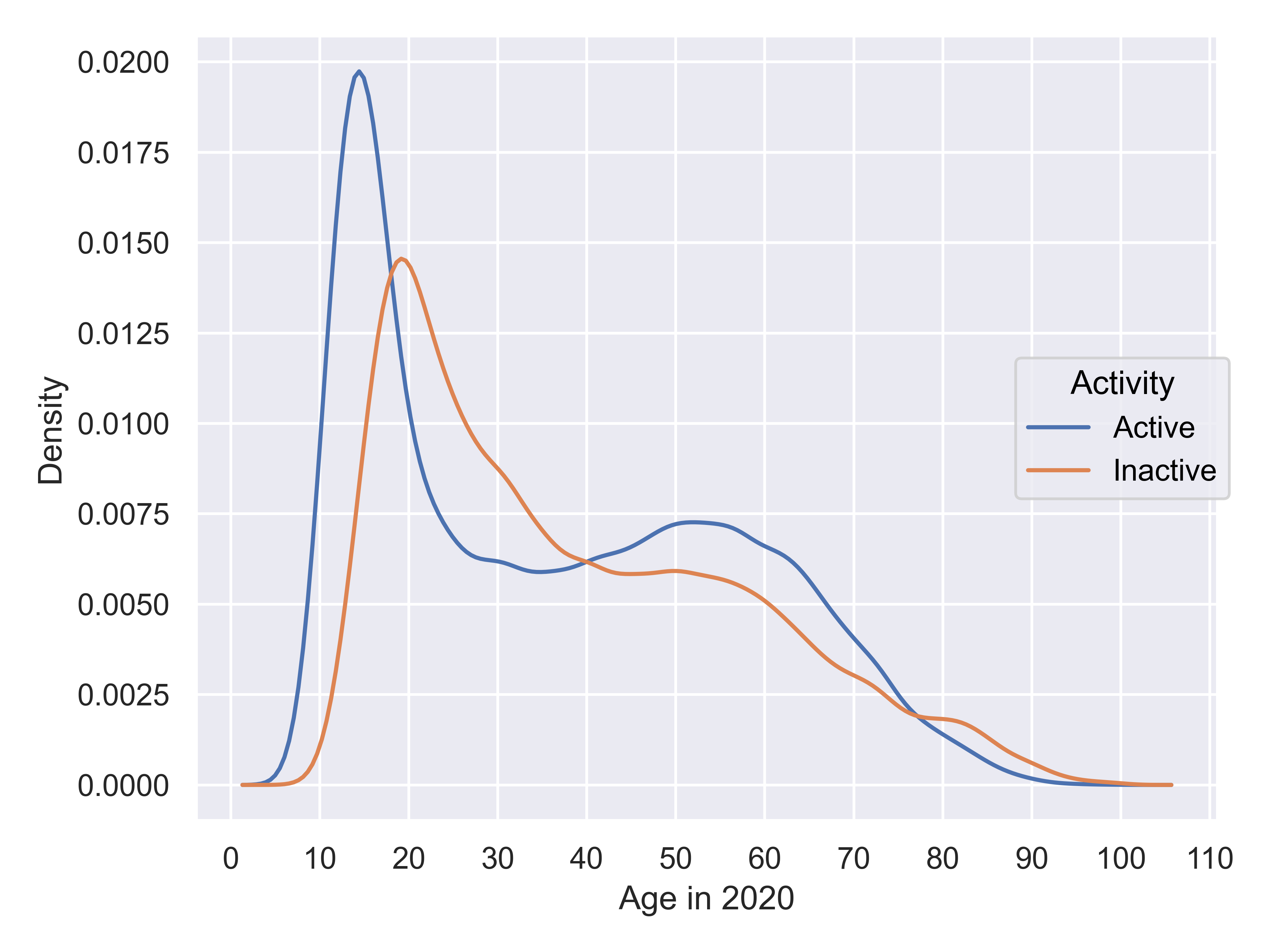
plt.figure(figsize=(6,4))
(
so.Plot(Chess2020, x = 'Age', color = 'Activity').
add(so.Line(), so.KDE()).
label(x = "Age in 2020", y = "Density").
scale(x = so.Continuous().tick(every=10)).
show()
)

We also have information on players’ gender. Chess has traditionally been perceived as very male-dominated, but let’s see if that stereotype holds up to the data.
ggplot(Chess2020, aes(x = Age, color = Sex)) +
geom_density(aes(y = after_stat(count)))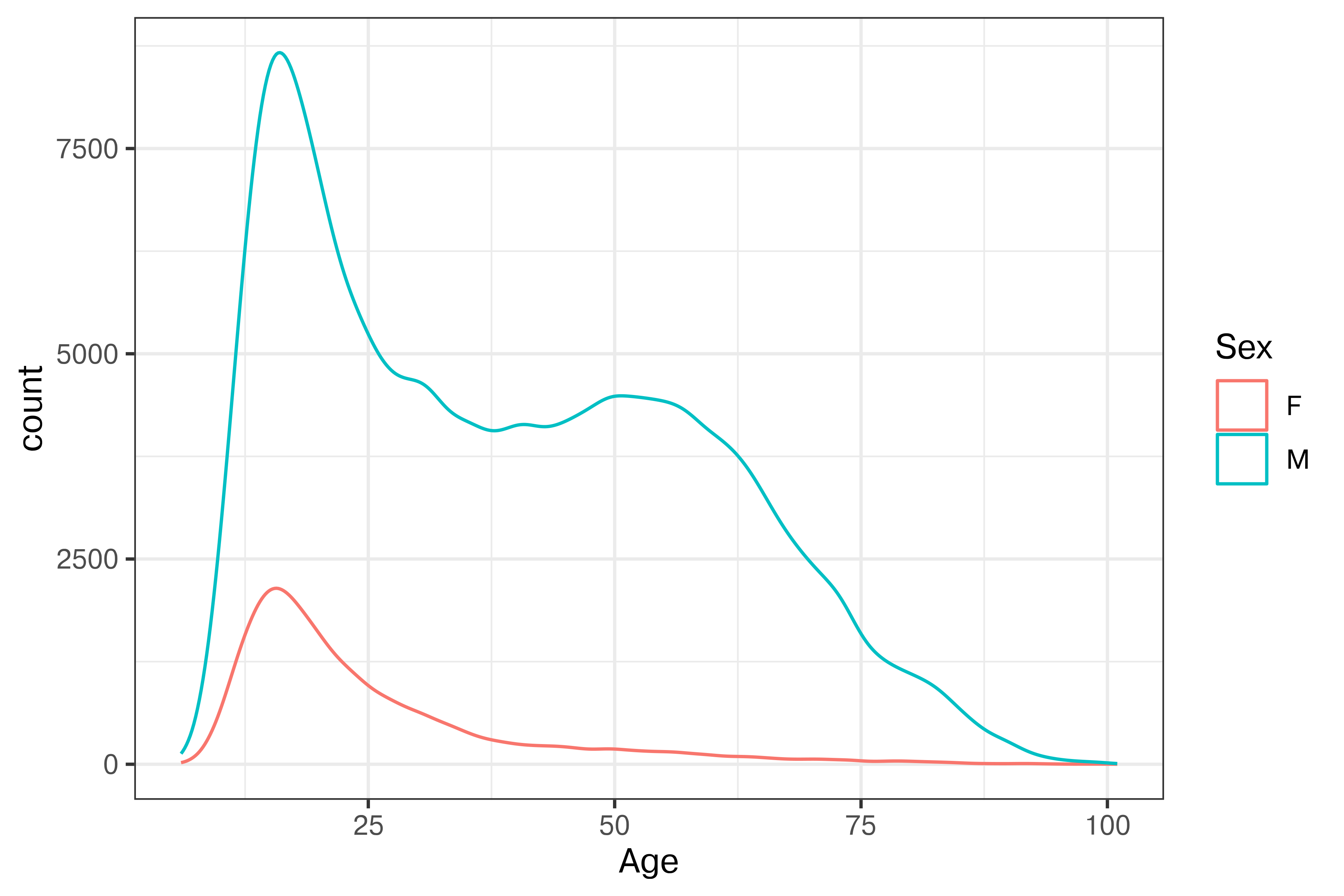
(
so.Plot(Chess2020, x = 'Age', color = 'Sex').
add(so.Line(), so.KDE(common_norm = True, common_grid = True)).
label(x = "Age in 2020", y = "Density").
scale(x = so.Continuous().tick(every=10)).
show()
)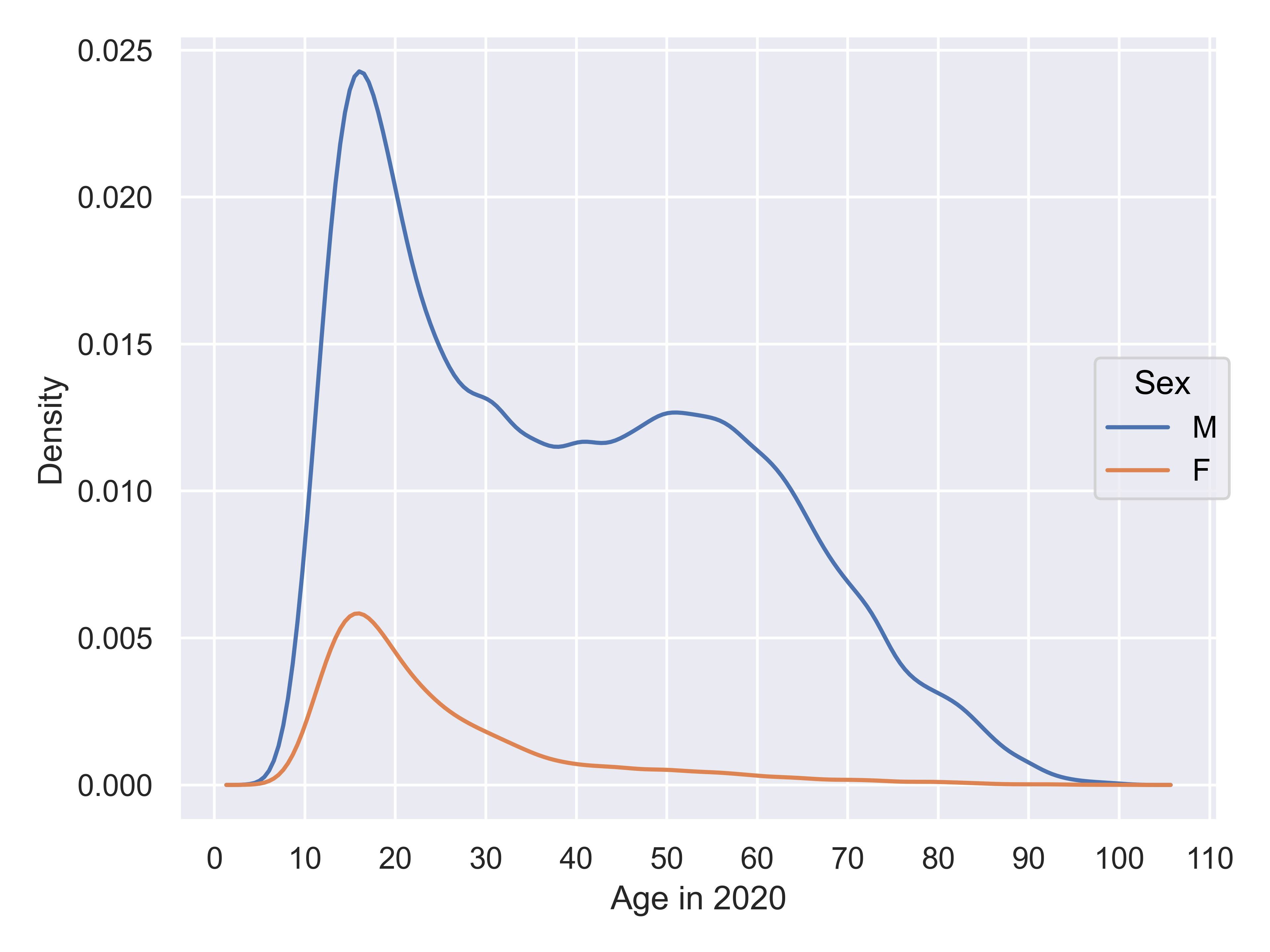
Ok, so there are clearly fewer females who have rating \(> 1000\) according to FIDE. What if we look at active vs. inactive players of both genders?
Chess2020 |>
ggplot(aes(x = Age, color = Sex)) +
geom_density(aes(y = after_stat(count))) +
facet_grid(Activity~.)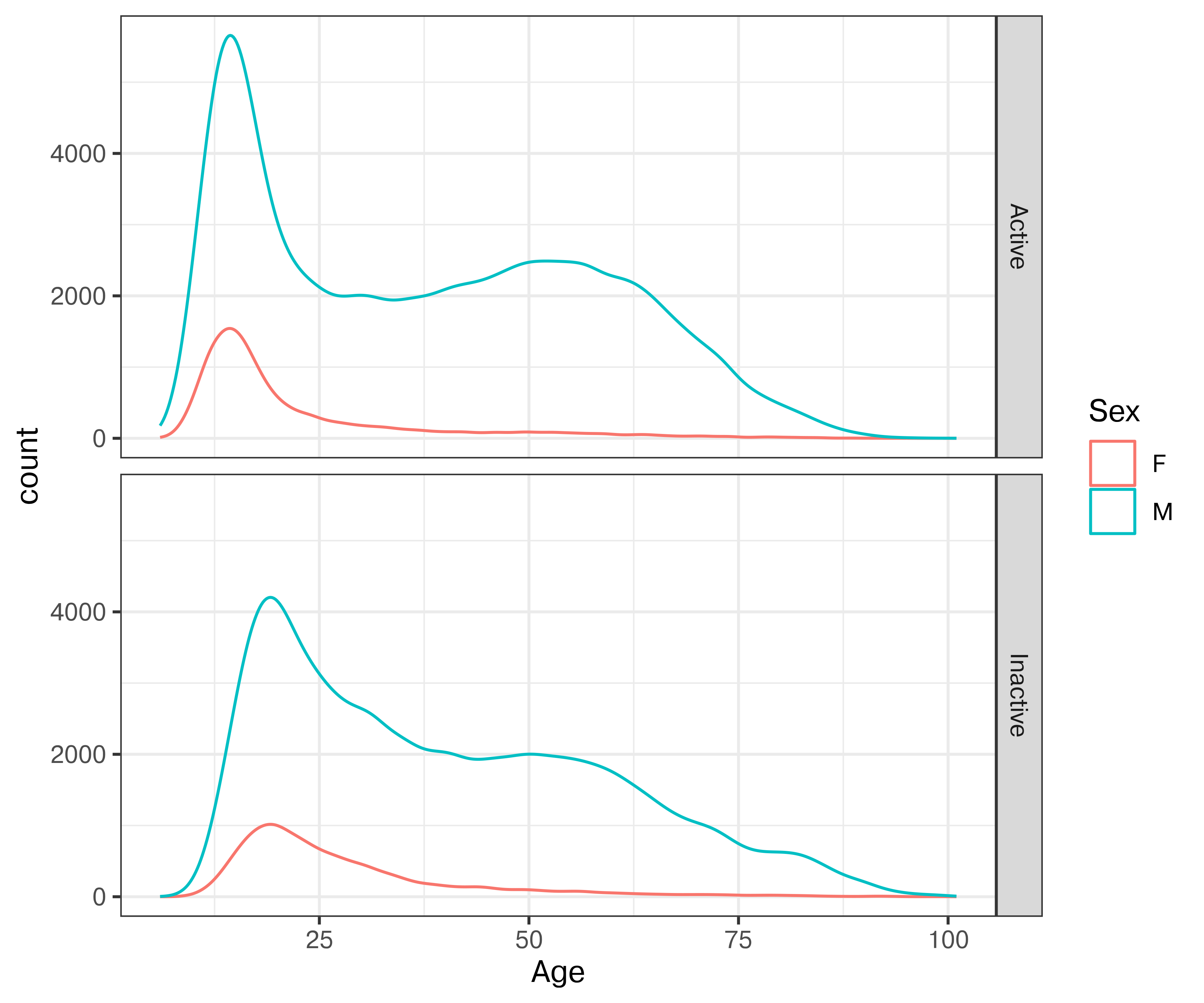
plt.figure(figsize=(6,5))
(
so.Plot(Chess2020, x = 'Age', color = 'Sex').
add(so.Line(), so.KDE(common_norm = True, common_grid = True)).
label(x = "Age in 2020", y = "Density").
facet(row = "Activity").
scale(x = so.Continuous().tick(every=10)).
show()
)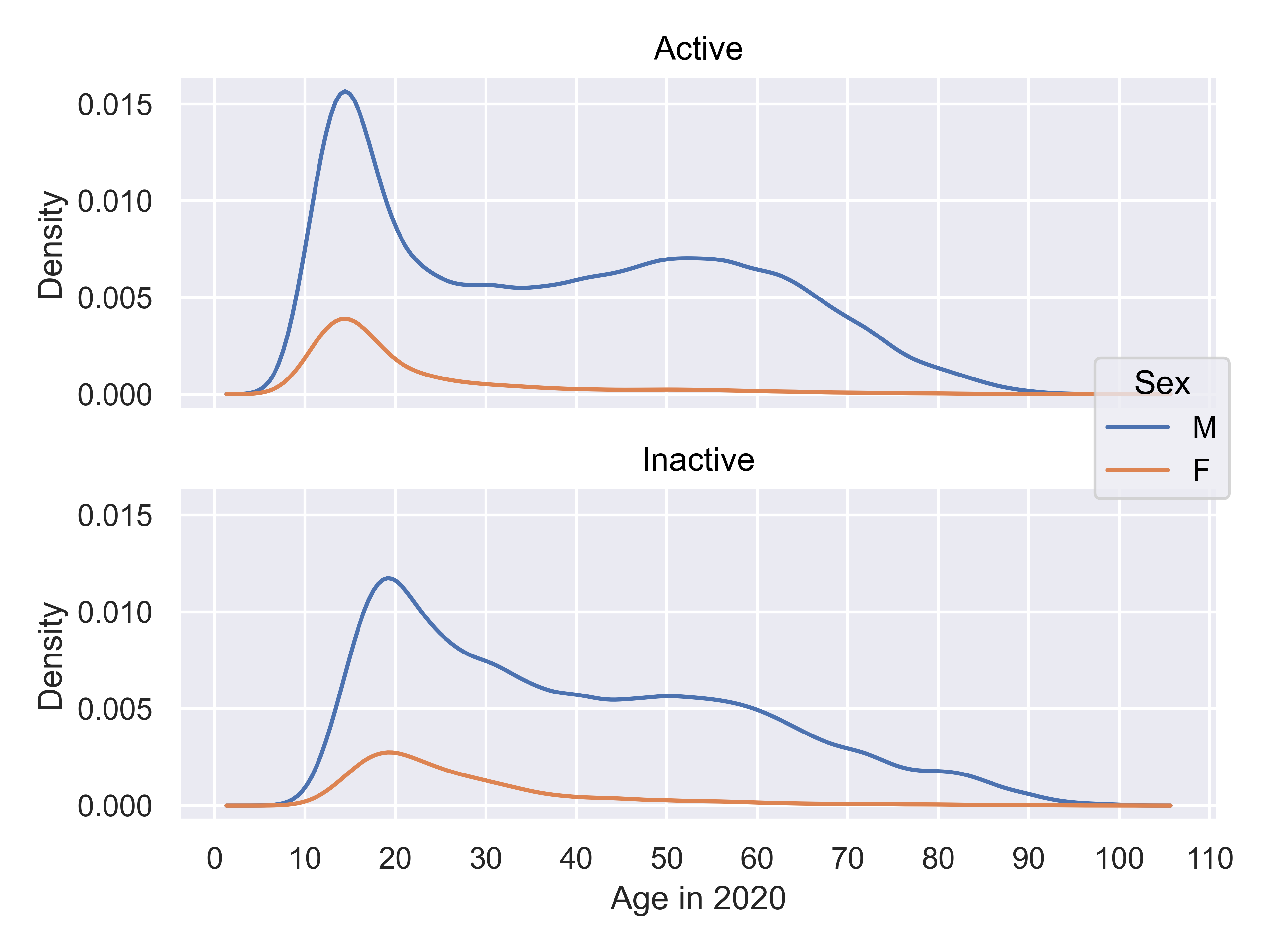

It is clear that there are a few interesting things going on in this plot. First, there is about a 5-year shift left in the age distribution of active players compared to inactive players, suggesting the possibility of demographic changes – either players starting earlier, young players reaching >1000 rating more frequently, or some other factor.
Second, it is clear that the behavior of men playing chess is different than that of women: men continue playing well into their 60s, while women usually quit before age 40.
Observations:
It is helpful, when possible, to show the full data, with aesthetics and facets chosen to highlight different variable combinations.
Summary statistics can be useful to highlight relationships amid noise.
Data reduction strategies (binning, alpha blending, sampling) can be useful when overplotting obscures the information present in the chart.
Annotations (labels, arrows, highlighted information, and captions) allow you to communicate specific parts of the data.
Good annotations help readers understand key findings, interpret data without having to reference legends, and see (and make sense of) structure, changes, and anomalies in the data.
In early 2020, the news started mentioning a cluster of pneumonia cases in China. The first cases were detected in the US in Washington state (Jan 20). A second case was confirmed on January 24 in Illinois, and the third-fifth cases were confirmed on January 26 in Arizona and California. By mid-February, Italy had become another hotspot.
On March 9, one of the classic graphics of the COVID-19 pandemic was released (?fig-flatten-curve), showing the power of both annotation and animation.
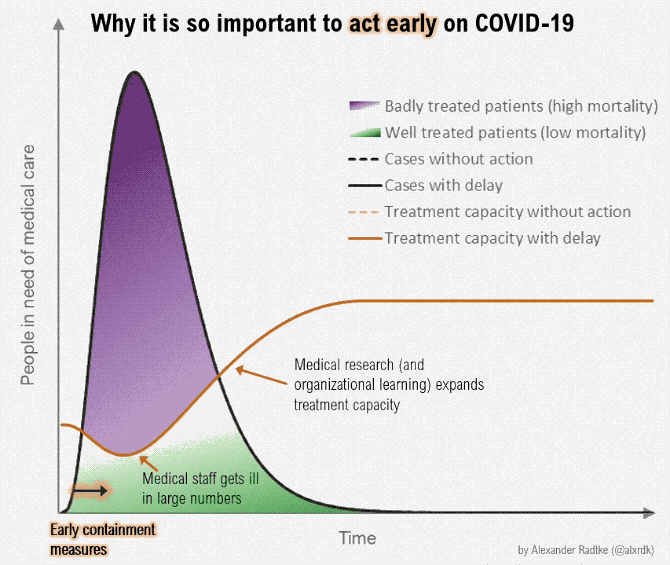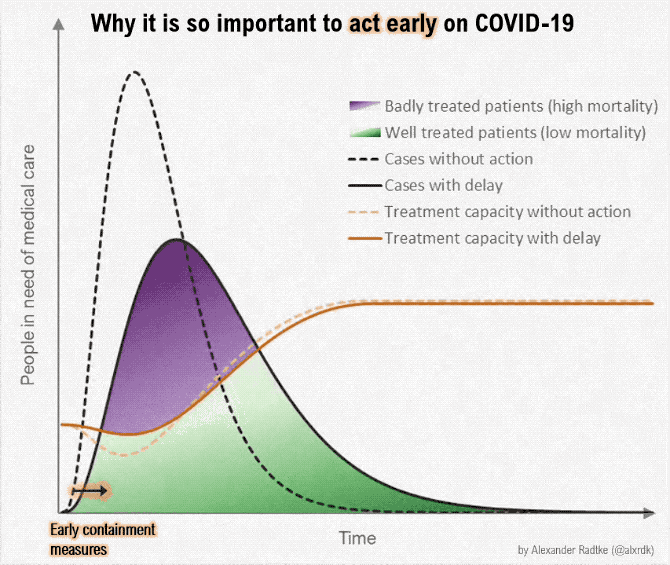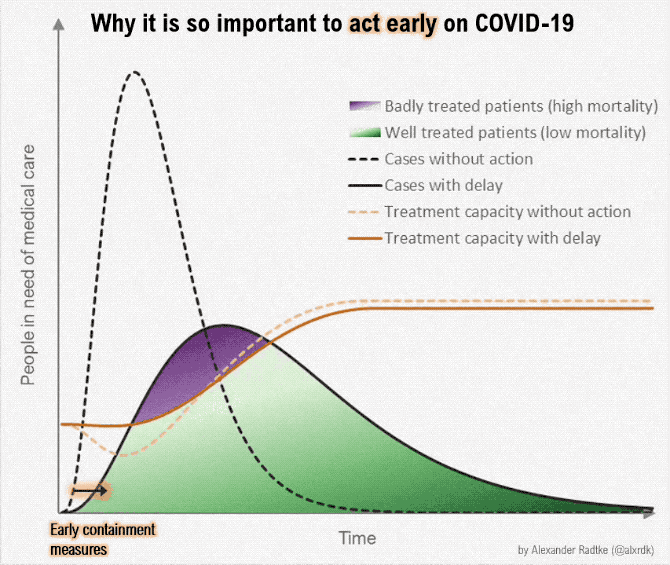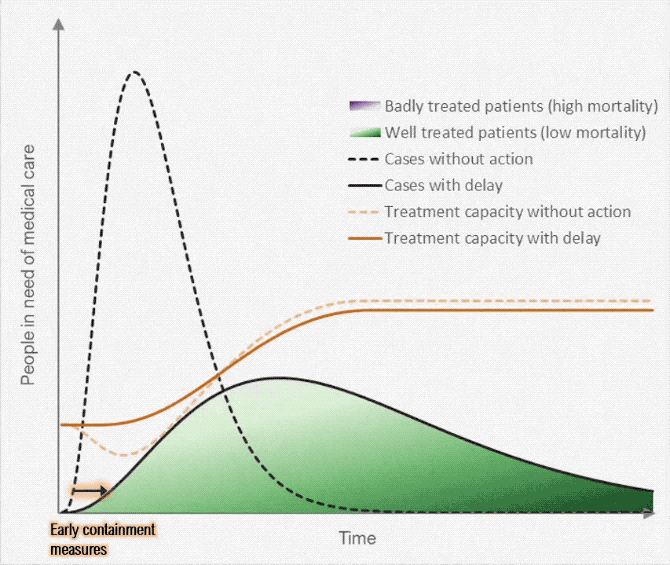 {#fig-flatten-curve width=“100%” fig-alt=“A plot labeled ‘Why it is so important to act early on COVID-19’, with x-axis showing time and y-axis showwing people in need of medical care. A shift to”early containment” pushes the case curve out over time (with the same number of cases overall), and simultaneously, a curve showing treatment capacity changes, until the treatment capacity is above the number of people in need of medical care. The proportion of the case curve above the treatment capacity is shaded in purple and corresponds to badly treated patients (high mortality), while the proportion of the case curve below treatment capacity represents properly cared-for patients (low mortality). As the curve moves, annotations pop up showing the effect of medical workers becoming ill (reduced treatment capacity) and the effect of medical research (increased treatment capacity).”}
{#fig-flatten-curve width=“100%” fig-alt=“A plot labeled ‘Why it is so important to act early on COVID-19’, with x-axis showing time and y-axis showwing people in need of medical care. A shift to”early containment” pushes the case curve out over time (with the same number of cases overall), and simultaneously, a curve showing treatment capacity changes, until the treatment capacity is above the number of people in need of medical care. The proportion of the case curve above the treatment capacity is shaded in purple and corresponds to badly treated patients (high mortality), while the proportion of the case curve below treatment capacity represents properly cared-for patients (low mortality). As the curve moves, annotations pop up showing the effect of medical workers becoming ill (reduced treatment capacity) and the effect of medical research (increased treatment capacity).”}
On March 11, the WHO declared COVID-19 a pandemic. By March 15, many states issued stay-home orders and only essential workers were allowed out.
In this example, we’ll stay on the same COVID theme, but we’ll use COVID (SARS-CoV-2) case counts in New York City, which was one of the big hotspots in the US early in the pandemic. This example will be done in ggplot2 because annotations tend to be more of a pain to create manually in seaborn.
library(readr)
library(lubridate)
library(dplyr)
library(tidyr)
library(stringr)
library(ggplot2)
library(zoo) # rollapply function
covid <- read_csv("../data/COVID-19_Daily_Counts_of_Cases,_Hospitalizations,_and_Deaths_20251020.csv") |>
select(date_of_interest:DEATH_COUNT) |>
mutate(date = mdy(date_of_interest)) |>
select(-date_of_interest, -PROBABLE_CASE_COUNT) |>
mutate(`Case_Count_-_Week_Average` = rollapply(CASE_COUNT, 7, mean, align="center", fill = "NA")) |>
pivot_longer(-date, names_to = "variable", values_to = "count") |>
mutate(variable = str_replace_all(variable, "_", " ") |> str_to_title()) |>
mutate(variable = str_replace_all(variable, pattern = c("Case Count" = "Cases", "Death Count" = "Deaths", "Hospitalized Count" = "Hospitalizations")))
head(covid)
## # A tibble: 6 × 3
## date variable count
## <date> <chr> <dbl>
## 1 2020-02-29 Cases 1
## 2 2020-02-29 Hospitalizations 1
## 3 2020-02-29 Deaths 0
## 4 2020-02-29 Cases - Week Average NA
## 5 2020-03-01 Cases 0
## 6 2020-03-01 Hospitalizations 1color_values <- c("Cases" = "#8780de", "Cases - Week Average" = "#544ad0", "Deaths" = "#ff7800", "Hospitalizations" = "#26a269")
alpha_values <- c("Cases" = .5, "Cases - Week Average" = 1, "Deaths" = 1, "Hospitalizations" = 1)
p <- filter(covid, date > ymd(20200101), date <= ymd(20201231)) |>
ggplot(aes(x = date, y = count, color = variable, alpha = variable)) +
geom_line() +
scale_alpha_manual("Counts", values = alpha_values) +
scale_color_manual("Counts", values = color_values) +
ylab("# Recorded People") +
ggtitle("SARS-CoV2 Cases, Hospitalizations, and Deaths in NYC") +
theme(axis.title.x = element_blank())
p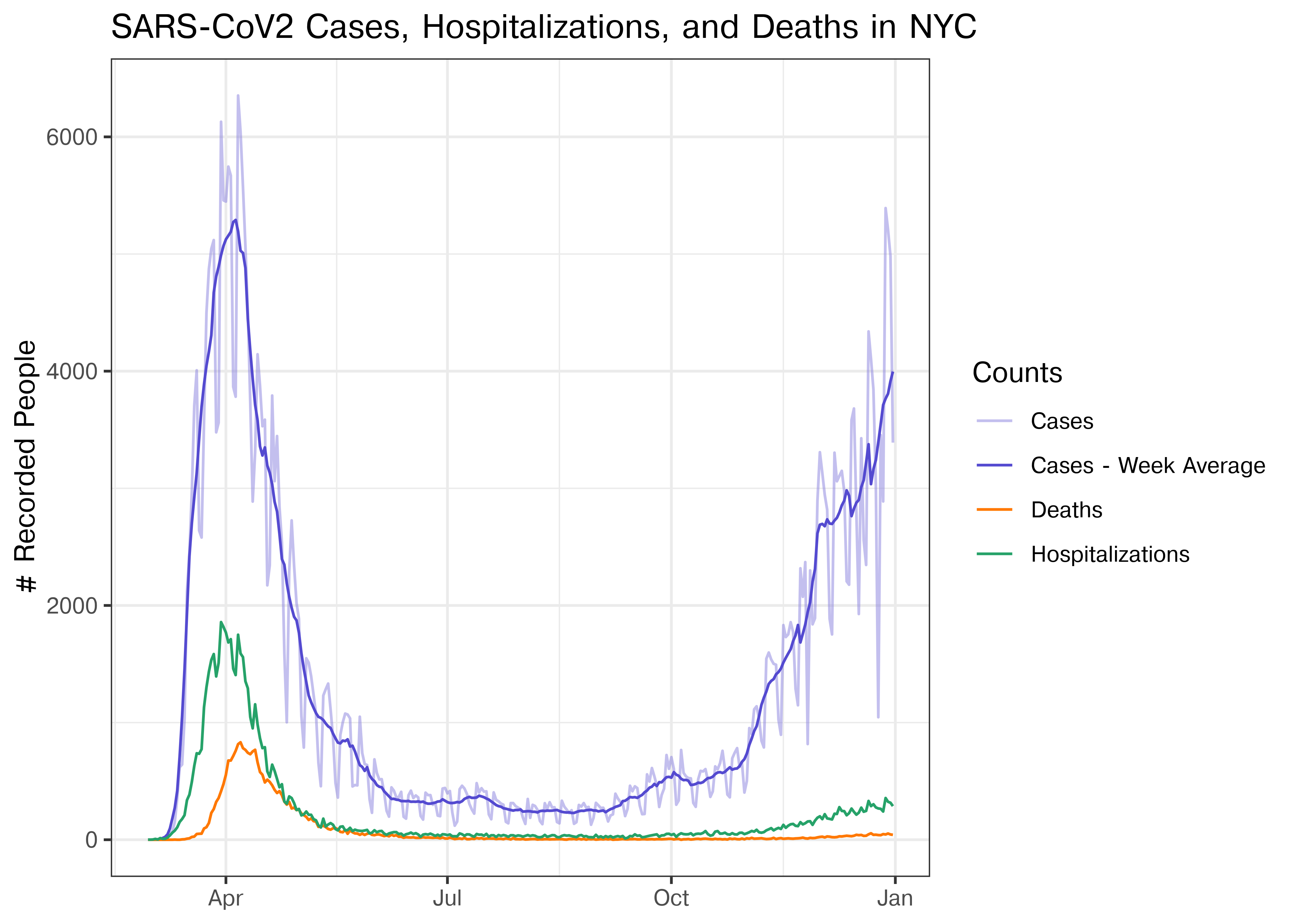
Now, this is a perfectly useful plot, but as you’ll remember from the short-term memory section, direct annotation can be more effective than using a legend. Let’s try that.
p_annotate_lines <- p +
theme(legend.position = "none") +
annotate("text", y = 2700, x = ymd("20201201"), label = "Cases (7d avg)", color = color_values[2], hjust = 1) +
annotate("text", y = 5500, x = ymd("20201225"), label = "Daily Cases\n (work week variation)", color = color_values[1], hjust = 1) +
annotate("text", y = 520, x = ymd("20201231"), label = "Hospitalizations", color = color_values[4], hjust = 1) +
annotate("text", y = -120, x = ymd("20201231"), label = "Deaths", color = color_values[3], hjust = 1)
p_annotate_lines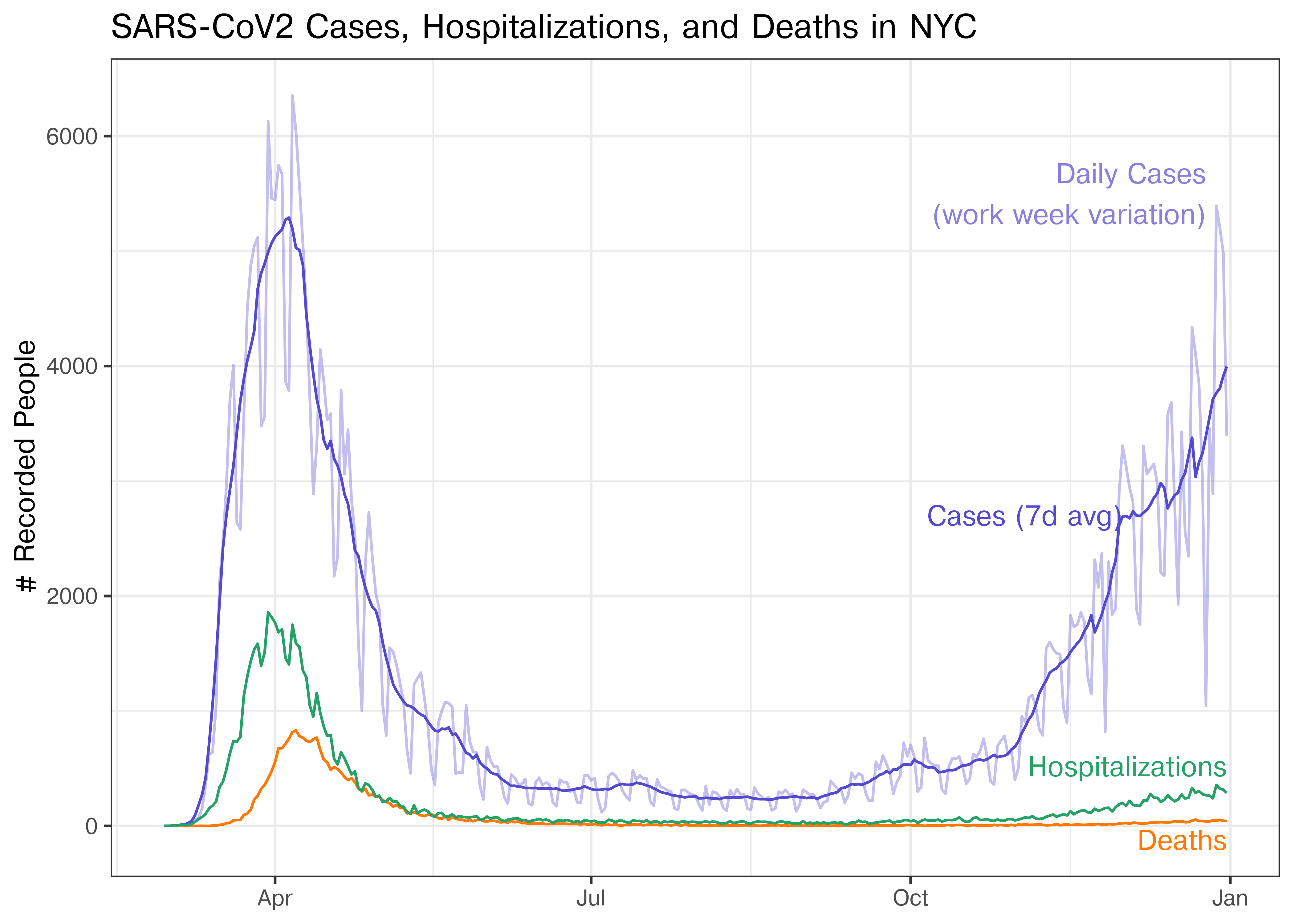
This is nice – we don’t have to refer to the legend and each line is labeled on the chart directly. We also have devoted more room on the chart to the data itself, which is a plus.
Annotations can also be used to provide useful contextual information.
Let’s see whether we can add this information to the chart too.
count_travel_adv <- filter(covid, date == ymd(20200328),
variable == "Cases - Week Average")$count
count_mass_graves <- filter(covid, date == ymd(20200410),
variable == "Deaths")$count
p_info_annot <-
p_annotate_lines +
scale_x_date(expand = expansion(add=c(75, 0)),
date_labels = "%b %y", date_breaks = "1 month") +
annotate("rect",
xmin = ymd(20200301), xmax = ymd(20200515), ymin = 0, ymax = 6500,
alpha = 0.05, fill = "black") +
annotate("text", x = ymd(20200520), y = 6500,
label = "Tests available for\nsevere cases only",
hjust = 0, vjust = 1, color = "grey30") +
annotate("segment", linetype = "dotted",
x = ymd(20200229), xend = ymd(20200229),
y = 500, yend = 0) +
annotate("segment", linetype = "dotted",
x = ymd(20200229), xend = ymd(20200224),
y = 500, yend = 500) +
annotate("text", x = ymd(20200224), y = 500,
label = "1st Pos\nCOVID Test", hjust = 1, vjust = 0.5) +
annotate("segment", linetype = "dotted",
x = ymd(20200315), xend = ymd(20200315),
y = 1350, yend = 0) +
annotate("segment", linetype = "dotted",
x = ymd(20200315), xend = ymd(20200305),
y = 1350, yend = 1350) +
annotate("text", x = ymd(20200305), y = 1350,
label = "NYC Schools\nShut Down", hjust = 1, vjust = 0.5) +
annotate("segment", linetype = "dotted",
x = ymd(20200328), xend = ymd(20200328),
y = 0, yend = count_travel_adv) +
annotate("segment", linetype = "dotted",
x = ymd(20200328), xend = ymd(20200318),
y = count_travel_adv, yend = count_travel_adv) +
annotate("text", x = ymd(20200318), y = count_travel_adv,
label = "CDC Issues\nTravel Advisory\nfor NY State",
hjust = 1, vjust = 0.5) +
annotate("segment", linetype = "dotted",
x = ymd(20200410), xend = ymd(20200410),
y = 0, yend = count_mass_graves) +
annotate("text", x = ymd(20200405), y = -100,
label = "Mass graves in NYC", hjust = 0, vjust = 1)
p_info_annot
We had to slightly extend the x-axis to accommodate the annotations, but this also has a rhetorical purpose – NYC didn’t have its first positive test until March 20, but the actual spread of cases in NYC was likely occurring well before that date – they just couldn’t be measured.
It is possible to add too many annotations to a chart and clutter it up. The last chart above is getting close, and it would be reasonable to e.g. omit the 1st positive covid test annotation because it’s implicit, but the additional context may also be useful.
What variations would you add?
When evaluating a chart that you hope to use for presentation, it is important to first think through what the goal of the chart is. Then, it can be helpful to work through the grammar of graphics to ensure that each element of the chart contributes to the overall goal.
Message
Mappings
Geometries
Scales and Transformations
Location scales
ggpp) to show both the compressed area and the total range.Color scales
Transformations
Facets and Layout
Annotations
When the COVID-19 outbreak started, many maps were using white-to-red gradients to show case counts and/or deaths. The emotional association between red and blood, danger, and death may have caused people to become more frightened than what was reasonable given the available information.↩︎
Lisa Charlotte Rost. What to consider when choosing colors for data visualization.↩︎
See this paper for more details. This is the last chapter of my dissertation, for what it’s worth. It was a lot of fun. (no sarcasm, seriously, it was fun!)↩︎