## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0
## Parcel ID: 10-24-201-025-000
##
## EASTDALE RENTALS LLC
## Attn: JEFF & ANITA EASTMAN
## 2501S 74ST
##
## LINCOLN, NE 68506
##
## Additional Owners
## No.
##
## 2250 SHELDON ST
## LINCOLN, NE 68503
##
## Prop Class: Residential Improved
##
## Primary Use: Conversion-Apt
##
## Living Units: 2
##
## Zonina: R4-Residential District
##
## Nbhd: 8NC01 - North Central -
## CVDU
##
## Tax Unit Grp: 0001
##
## Schl Code Base: 55-0001 Lincoln
##
## Exemptions:
##
## Flaas:
##
## GBA: 0
##
## NRA:
##
## Location:
##
## Parking Tvpe:
##
## Parkina Quantitv:
##
## ENGLESIDE ADDITION, BLOCK 2, Lot 23
##
## LANCASTER COUNTY APPRAISAL CARD
## Tax Year: 2025
##
## Date Type Sale Amount Validity
##
## 05/20/2022 Improved $0 Disqualified
## 04/23/1996 Improved $37,000 Disaualified
## 09/08/1994 Improved $0 Disqualified
##
## Number Issue Date
##
## Date Time Process
##
## 07/11/2022 Interview and Measure - 01
## 11/20/2015 11:45 AM No Answer At Door, Exterior - 04
## 07/15/2010 Field Review - 08
##
## 05/04/2010 No Answer At Door, Measured - 05
## 09/17/2008 Field Review - 08
##
## Case # Status Action
##
## Amount _ Status Type
##
## Run Date: 7/15/2025 12:23:27 PM
##
## Description
##
## Reason
## General Review
## General Review
## Final Review
## General Review
## Final Review
##
## Current
## Prior
## Cost
##
## Income
##
## Page 1 of 2
##
## Multi Inst.Type Instrument #
## Warranty Deed 2022025796
## Warranty Deed 1996016959
## Death Certificate 1994045456
##
## Appraiser Contact-Code
## MRC Tenant - 2
##
## afo
##
## CAB
##
## TMJ
##
## CAB
##
## Land Buildina Total
## $45,000 $124,700 $169,700
## $45,000 $124,700 $169,700
## $45,000 $115,700 $160,700
## $25,000 $69.400 $94,400
## $25,000 $69.400 $94,400
##
## Land Buildina Total Method
## $45,000 $124,700 $169,700 IDXVAL
## $45.000 $124,700 $169,700 IDXVAL
##
## $158,280 Market $332,300 GRM $169,700
## $0 MRA $160,100 Ovr
##
## Method Type
## Site RPI-Primary Interior
##
## Total Acres 0.15 GIS SF 6402
##
## ACSF Units Inf1 Fact1
##
## Inf2 Fact2
##
## InflC FactC Land Value
##
## 45,000
##
## Avg Unit Val
## 45,000
##
## Mkt Land Total $45,000
## Taxable Aq Land Total $0


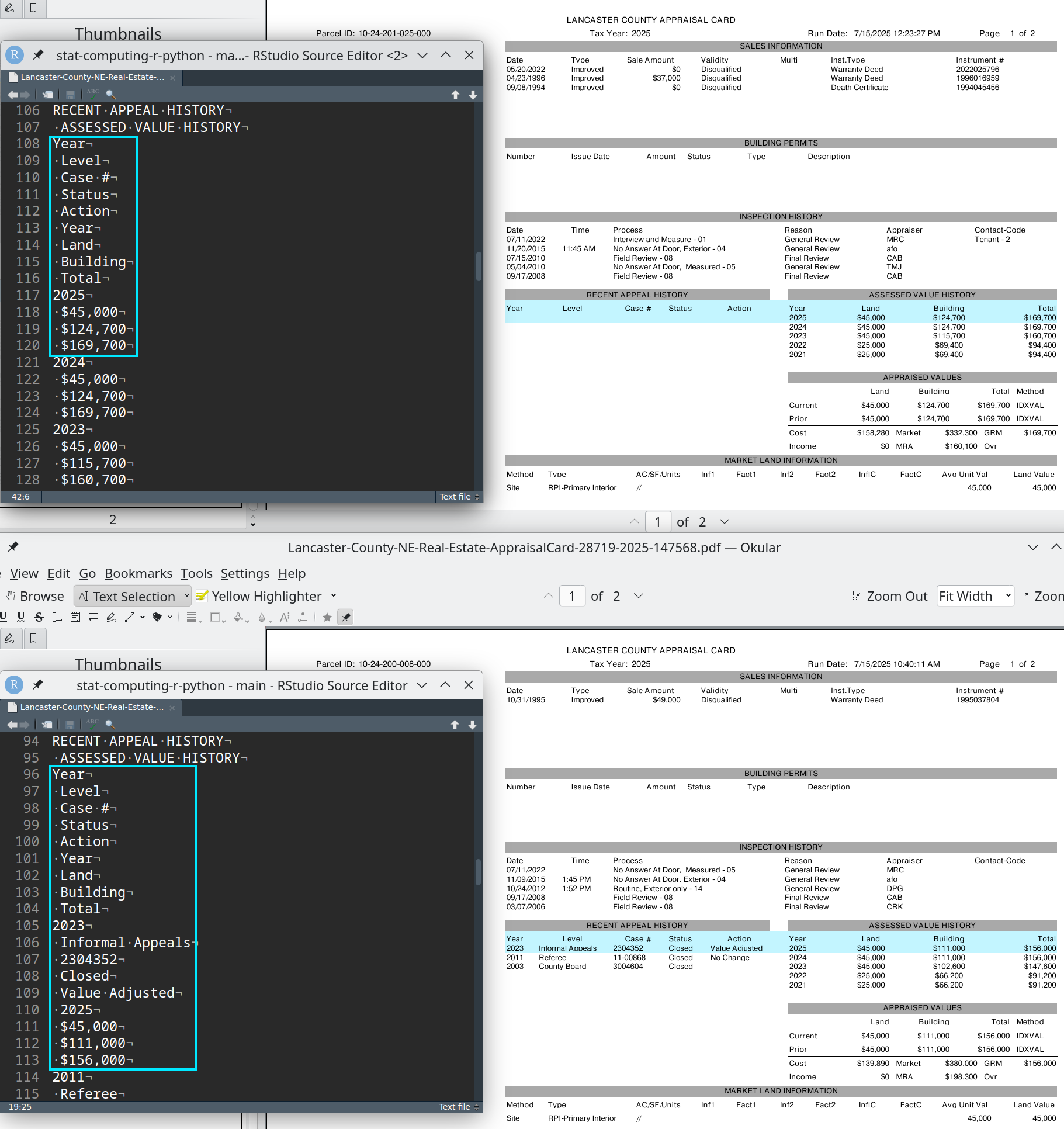
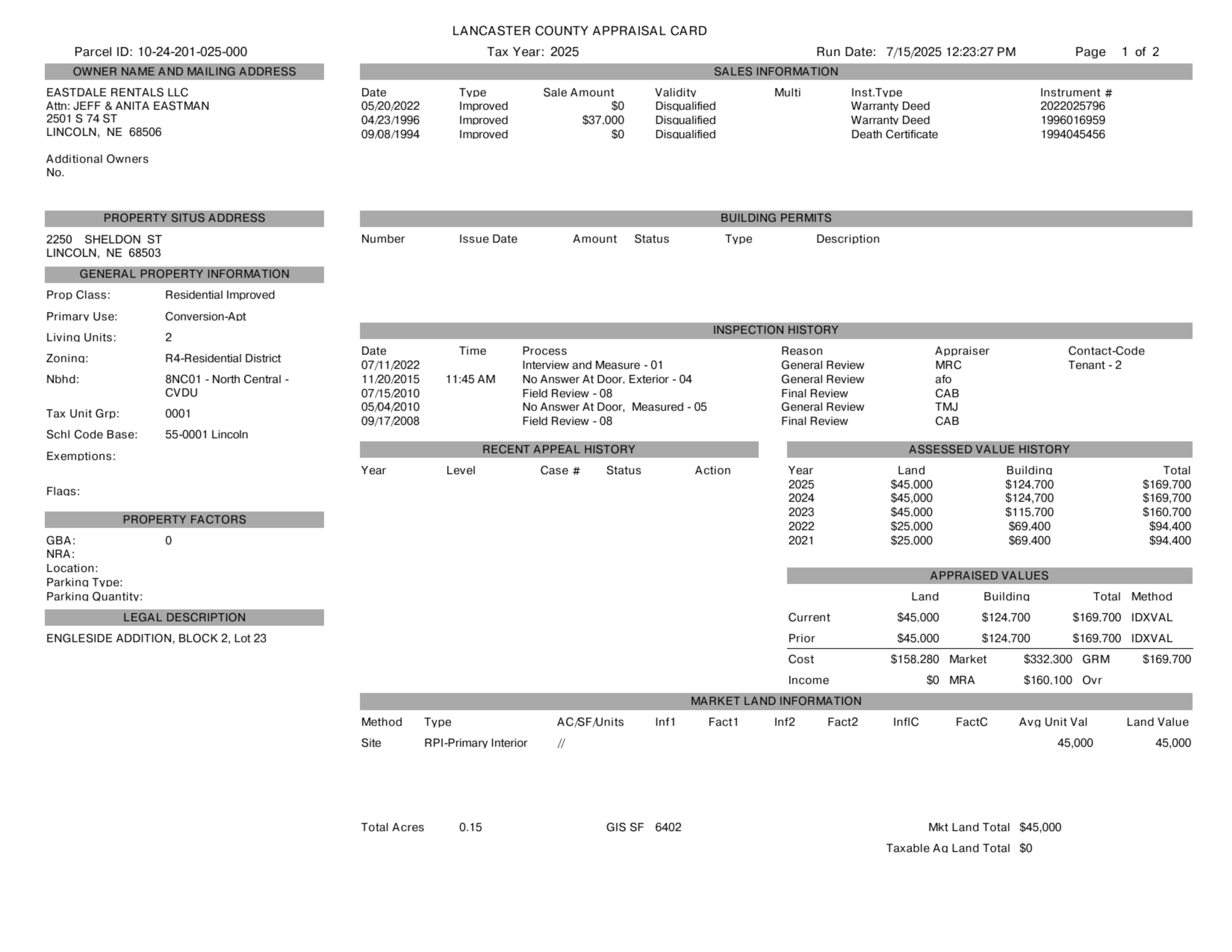
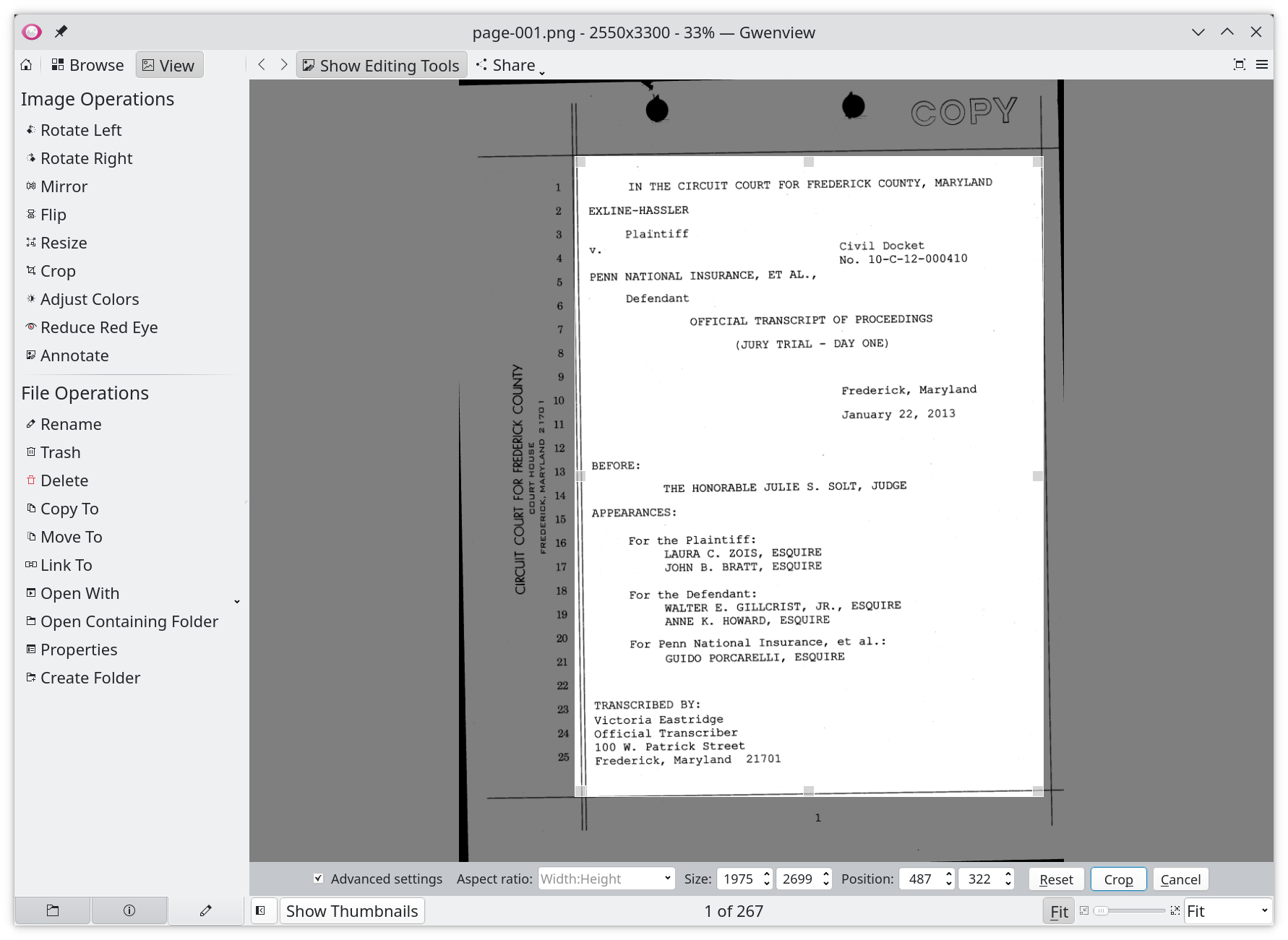
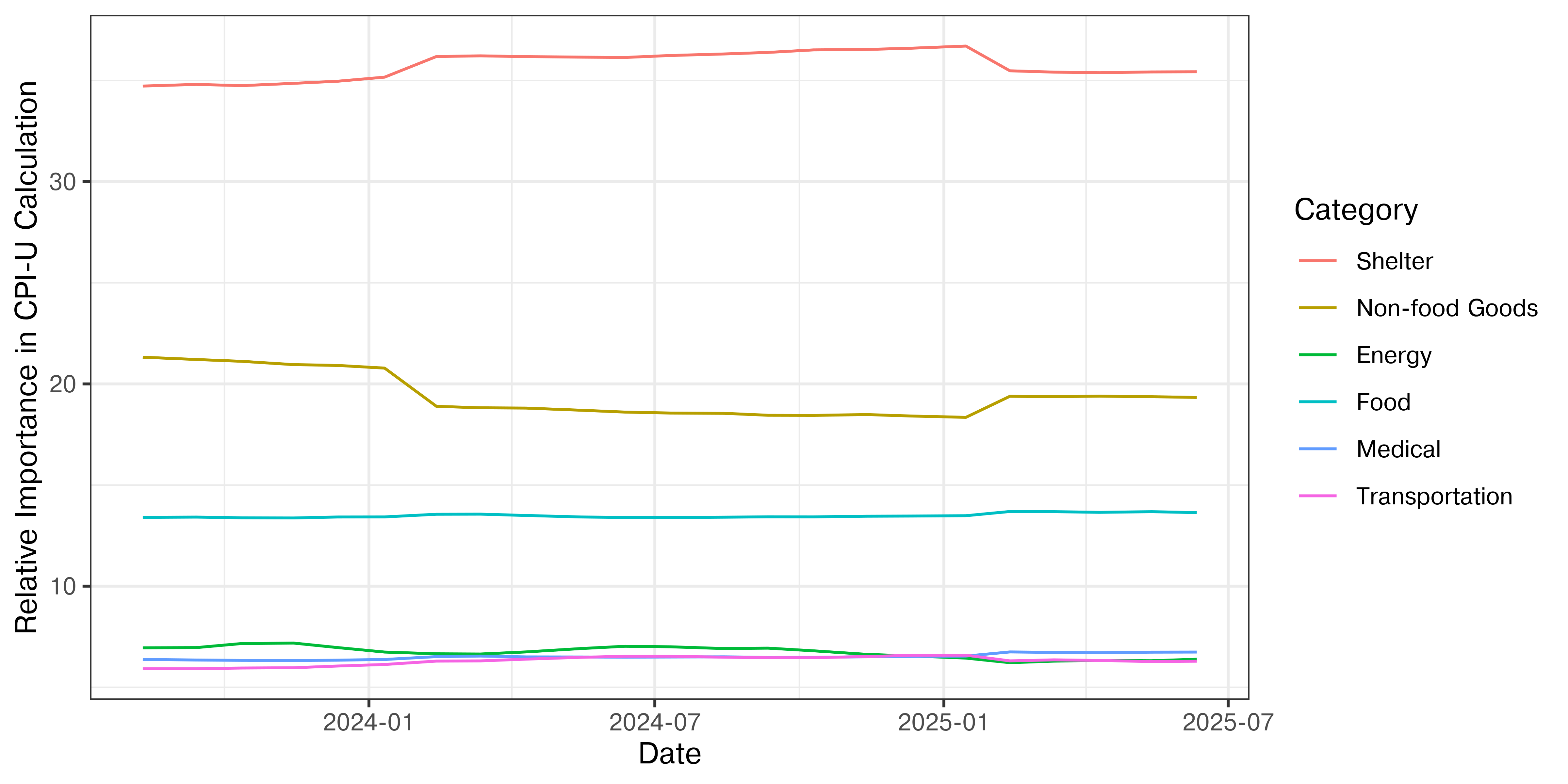
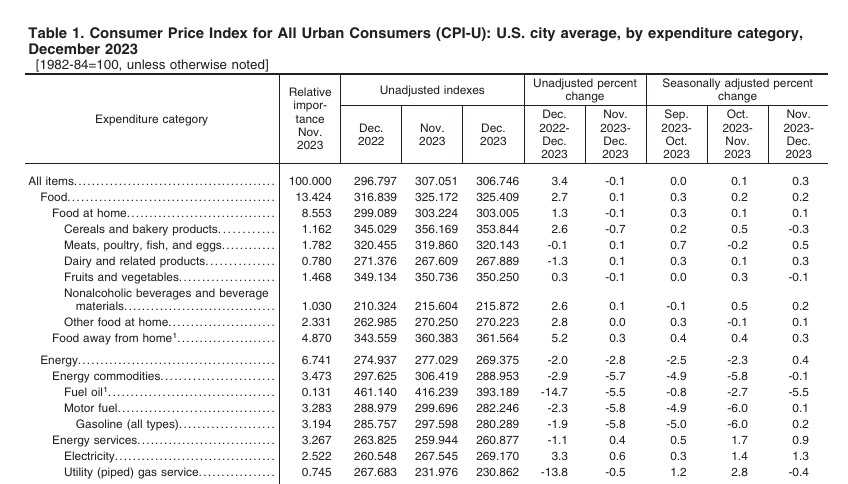
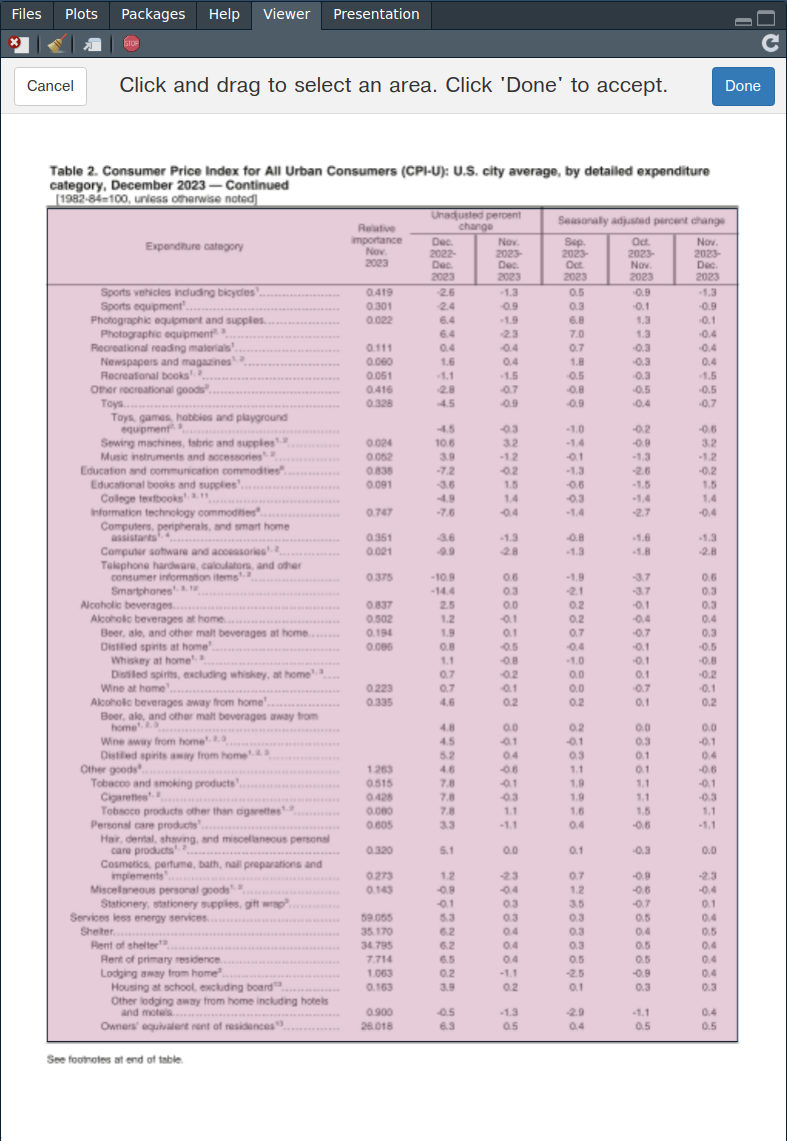
{kind=link}